Считаем буквы в произведениях русской литературы
Вы когда-нибудь задавались вопросом, какая буква русского алфавита встречается в текстах чаще остальных? Именно поиском ответа на этот вопрос я и собираюсь заняться. A пока, вы не знаете результатов моего маленького исследования, я предлагаю вам угадать пять самых распространенных букв нашего алфавита. Готовы?
Итак, как говорил один мой знакомый, хватаясь за баранку своего автомобиля, поехали.
Для начала нам понадобятся тексты, на которых мы будем практиковаться. Я выбрал три литературных произведения наших классиков: «Война и мир» Льва Николаевича Толстого, «Тихий Дон» Михаила Шолохова, «Мастер и Маргарита» Михаила Булгакова. Почему эти произведения? Просто первые два — это единственные, которые я читал в школе, а «Мастер и Маргариту» мы с женой смотрели по телевизору и поэтому, я, немного разбираюсь в теме.
Теперь нам нужно каким-то образом посчитать в них количество каждой буквы алфавита и общее количество букв. Как же это сделать? Можно пойти самым простым путем, как, например, делает мой начальник. Для этого нужно пойти в библиотеку, взять четыре тома «войны и мир», придти домой и заняться пересчетом букв, затем таким же образом поступить с остальными книгами. Конечно, на это уйдет много времени, но мой начальник очень трудолюбивый человек, а еще у него есть подчиненные. Можно им по тому раздать, a, если не посчитают, или ошибутся — «премии лишу».
Этот способ мне сразу не понравился, и я решил написать программу, которая сделает всю работу за нас. Ниже прилагается код программы, написанной на perl. Она подсчитывает общее количество букв в тексте, а также количество каждой из букв алфавита и их процентное содержание.
use strict;
use locale;
use POSIX qw (locale_h);
setlocale(LC_CTYPE, ‘ru_RU.CP1251’);
setlocale(LC_ALL, ‘ru_RU.CP1251’);
my @letters = qw(А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я);
my @out = qw(0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0);
open (TEXT, «
Для наглядности я немного доработал полученные данные в excel. 
Как говориться, результат налицо. Самая популярная буква русского алфавита — это «О», а пятерка выглядит следующим образом: «О», «А», «Е», «И», «Н».
Теперь осталось ответить на самый главный вопрос. Зачем все это нужно?
Эту информацию, например, можно использовать, когда Леонид Якубович разрешит нам открыть любые пять букв. Я надеюсь, теперь вы знаете, какие буквы надо называть?
А если говорить серьезно, то нахождение частот встречаемости символов используется намного чаще, чем вы можете себе представить. Эта задача входит в алгоритм Хаффмана, который применяется во многих современных программах сжатия данных.
Частота букв в русском языке
Написал забавный php-скрипт. Погонял через него все тексты на « Спектаторе» на предмет языка. Всего в текстах употребляется 39110 разных словоформ. Сколько именно разных слов — определить довольно сложно. Чтобы хоть как-то приблизиться к этой цифре, я брал только первые 5 букв слова и сравнивал их. Получилось 14373 таких комбинаций. С большой натяжкой это можно назвать словарным запасом « Спектатора».
Потом я взял слова и иследовал их на предмет частоты повторения букв. В идеале надо брать какой-нибудь словарь, для полноты картины. Прогонять тексты нельзя, нужно только уникальные слова. В тексте же одни слова повторяются чаще, чем другие. Итак, получились следующие результаты:
о — 9.28%
а — 8.66%
е — 8.10%
и — 7.45%
н — 6.35%
т — 6.30%
р — 5.53%
с — 5.45%
л — 4.32%
в — 4.19%
к — 3.47%
п — 3.35%
м — 3.29%
у — 2.90%
д — 2.56%
я — 2.22%
ы — 2.11%
ь — 1.90%
з — 1.81%
б — 1.51%
г — 1.41%
й — 1.31%
ч — 1.27%
ю — 1.03%
х — 0.92%
ж — 0.78%
ш — 0.77%
ц — 0.52%
щ — 0.49%
ф — 0.40%
э — 0.17%
ъ — 0.04%
Тем, кто поедет на « Поле чудес», советую заучить эту таблицу наизусть. И называть слова в таком порядке. Так, например, казалось бы, такая « привычная» буква « б» употребляется реже, чем « редкая» буква « ы». Помнить надо также и то, что в слове не одни гласные. И что если вы угадали одну гласную, то нужно начинать идти по согласным. И кроме того, слово угадывается именно по согласным. Сравните: « **а**и*е» и « ср*вн*т*». И в том и в другом случае — это слово « сравните».
И еще одно соображение. Как вы учили английский? Помните? Э пен, э пенсил, э тэйбл. Что вижу — о том и пою. А смысл. Как часто вы в нормальной жизни говорите слово « карандаш»? Если задача — научить говорить как можно быстрее и эффективнее, то и учить надо соответствующе. Проводим анализ языка, выделяем самые употребимые слова. И учить начинаем именно с них. Чтобы более-менее говорить на английском языке, достаточно всего полторы тысячи слов.
Еще одно баловство: составлять слова из букв случайным образом, но учитывая частоту появления, чтобы было похоже на нормальные слова. В первой же десятке « случайных» четырехбуквенных слов выскочило « осел». В следующей полсотне — слова « мчим» и « нато». Но, увы, очень много неблагозвучных комбинаций, таких, как « блтт» или « нрро».
Поэтому — следующий шаг. Я разбил все слова на двухбуквенные сочетания и начал случайным образом (но с учетом частоты повторения) комбинировать их. Стали в больших количествах получатся слова, похожие на « нормальные». Например: « коивдиот», « воабма», « апый», « депоид», « дебяко», « орфа», « поеснавы», « озза», « ченя», « риторя», « урдеед», « утоичи», « стых», « сапоть», « гравда», « абабап», « обарто», « еелует», « лярезы», « мыни», « бромомер» и даже « тодебыст».
Куда применить. есть варианты. Например, написать генератор красивых фирменных игривых имен. Для йогуртов. Типа, « мемолисо» или « уторорерто». Или — генератор футуристических стихов « Бурлюк-php»: « опелдиий миатон, линоаз окмиая. деесопен одесон».
И есть еще один вариант. Надо попробовать.
Некоторые статистические данные об использовании русских слов:
После заметки мне пришло вот такое письмо:
Проанализировав статью « Язык до Киева доведет» и ту ее часть, где Вы описываете свою программу, возникла идея.
Вами написанный скрипт кажется мне предназначенным абсолютно не для « Поля чудес» в большей мере, а для другого.
Первое самое разумное применение результатов работы Вашего скрипта — определение порядка букв при программировании кнопок для мобильных устройств. Да, да — именно в мобильниках и нужно все это.
Я распределил это по волнам (см. рисунок)
Далее распределение по кнопкам:
1. Все буквы из первой волны уходят на 4 кнопки в первый ряд
2. Все буквы из второй волны тоже на остальные 4 кнопки в тот же первый ряд
3. Все буквы из третьей волны туда же на оставшиеся две кнопки
4. 4,5 и 6 волны уходят во второй ряд
5. 7,8,9 волны уходят на третий ряд, причем 9-я волна уходит вся полностью (не смотря на кажущееся большое количество букв) в третий ряд 9-й кнопки, что-бы 10 кнопку оставить под всякие там знаки препинания (точка, запятая и прочее).
Я думаю все понятно и так, без детальных обьяснений. Но все же не могли бы Вы обработать Вашим скриптом (включая знаки припинания) тексты следующего содержания:
А потом выложить статистику? Мне показалось? что тексты максимально отражают нашу современную речь, а ведь мы как говорим, так и пишем sms.
Заранее большое спасибо.
Итак, анализировать частоту повторения букв можно двумя способами. Способ 1. Взять текст, найти в нем уникальные (не повторяющиеся) словоформы и анализировать их. Способ хорош для построения статистики по словам русского языка, а не по текстам. Способ 2. Не искать в тексте уникальные слова, а сразу перейти к подсчету частоты повторения букв. Получаем частоту букв в русском тексте, а не в русских словах. Для создания клавиатур и прочего нужно использовать именно этот способ: на клавиатуре набираются именно тексты.
Клавиатуры должны учитывать не только частоту букв, но и самые упортебимые слова (словоформы). Не так уж и трудно догадаться, какие именно слова самые употребимые: это, во-первых, служебные части речи, ибо роль у них такая — служить всегда и везде, и местоимения, роль у которых не менее важная: заменять в речи любую вещь/человека (это, он, она). Ну и основные глаголы (быть, сказать). По результатам анализа перечисленных выше текстов я получил такие самые « популярные» слова: « и, не, в, что, он, я, на, с, она, как, но, его, это, к, а, все, ее, было, так, же, то, сказал, за, ты, о, у, ему, мне, только, по, меня, бы, да, вы, от, был, когда, из, для, еще, теперь, они, сказала, уже, него, нет, была, ей, быть, ну, ни, если, очень, ничего, вот, себя, чтобы, себе, этого, может, того, до, мы, их, ли, были, есть, чем, или, ней» и так далее.
Возвращаясь к клавиатурам — очевидно, что в клавиатуре буквосочетания « не», « что», « он», « на» идругие должны находится как можно ближе друг к другу, или если не вплотную, то каким-то наиболее оптимальным образом. Нужно провести исследования, каким именно образом пальцы движутся по клавиатуре, найти самые « удобные» позиции и поместить в них самые употребляемые буквы, не забывая, однако, про буквосочетания.
Проблема, как всегда, одна: даже если и получиться создать Уникальную Клавиатуру, куда деть миллионы людей, которые уже привыкли к qwerty/йцукен?
Запятая употребляется в 2 раза чаще, чем точка. А точка на стандартной русской клавиатуре расположена удобней.
Статистика по приведенным выше текстам:
По уникальным словам:
о — 9.36%
а — 8.40%
е — 8.08%
и — 6.91%
н — 6.12%
с — 5.67%
т — 5.49%
р — 5.30%
л — 5.00%
в — 4.67%
п — 3.38%
у — 3.17%
к — 3.14%
м — 2.97%
д — 2.72%
я — 2.50%
ь — 2.08%
ы — 2.06%
з — 1.85%
б — 1.61%
г — 1.47%
ш — 1.32%
ч — 1.22%
й — 1.21%
ж — 1.01%
ю — 0.99%
х — 0.97%
щ — 0.48%
ц — 0.37%
ф — 0.20%
э — 0.06%
ъ — 0.05%
По текстам в целом:
о — 11.35%
е — 8.93%
а — 8.23%
н — 6.71%
и — 6.48%
т — 6.17%
с — 5.22%
л — 4.95%
в — 4.47%
р — 4.17%
к — 3.35%
д — 2.97%
м — 2.93%
у — 2.86%
п — 2.39%
я — 2.17%
ь — 2.09%
ы — 1.90%
г — 1.811%
б — 1.77%
ч — 1.67%
з — 1.65%
ж — 1.14%
й — 1.09%
ш — 0.89%
х — 0.79%
ю — 0.66%
э — 0.33%
ц — 0.29%
щ — 0.29%
ф — 0.10%
ъ — 0.02%
Таблица частотности букв русского алфавита
Частотность — термин лексикостатистики, предназначенный для определения наиболее употребительных слов. Расчёт осуществляется по формуле:
где Freqx — частотность слова «x», Qx — количество словоупотреблений слова «x», Qall — общее количество словоупотреблений. В большинстве случаев частотность выражается в процентах. В словарях частотность слов может отражаться пометками — употребительное, малоупотребительное и т. д.
Аналогичным образом определяется частотность для букв. Бо́льшая частотность согласных на данном отрезке текста (например, в стихотворениях) получила название аллитерации. Высокие показатели частотности гласных называются ассонансом. Частотный анализ используется в криптографии для выявления наиболее частотных букв того или иного языка.
Частотность слов и букв являлась важнейшим инструментов криптоанализа в эпоху до повсеместного распространения блочных шифров.
Не следует путать термины частотность и частота.
Частотность букв русского языка [ править | править код ]
Статистика частотности букв русского языка (на материале НКРЯ): [1]
Частотный анализ – это один из методов криптоанализа, основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей как в открытом тексте, так и шифрованном тексте, которое с точностью до замены символов будет сохраняться в процессе шифрования и дешифрования.
Кратко говоря, частотный анализ предполагает, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом в случае моноалфавитного шифрования, если в шифрованном тексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двубуквенным последовательностям), триграммам в случае полиалфавитных шифров.
Метод частотного анализа известен с еще IX-го века и связан и именем Ал-Кинди. Но наиболее известным случаем применения такого анализа является дешифровка египетских иероглифов Ж.-Ф. Шампольоном в 1822 году.
Данный вид анализа основывается на том, что текст состоит из слов, а слова из букв. Количество различных букв в каждом языке ограничено и буквы могут быть просто перечислены. Важными характеристиками текста являются повторяемость букв, пар букв (биграмм) и вообще m-ок (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие.
Если – число появлений m-граммы ai1ai2. aim в тексте T, а L – общее число подсчитанных m-грамм, то опыт показывает, что при достаточно больших L частоты
для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частоту считают приближением вероятности P (ai1ai2. aim) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
В представленной ниже таблице приводятся частоты встречаемости букв в русском языке (в процентах):
| Буква алфавита | Показатель частоты встречаемости | Буква алфавита | Показатель частоты встречаемости |
|---|---|---|---|
| А | 0,062 | Р | 0,04 |
| В | 0,038 | Т | 0,053 |
| Д | 0,025 | Ф | 0,002 |
| Ж | 0,007 | Ц | 0,004 |
| И | 0,062 | Ш | 0,006 |
| К | 0,028 | Ъ, Ь | 0,014 |
| М | 0,026 | Э | 0,003 |
| О | 0,09 | Я | 0,018 |
Имеется мнемоническое правило запоминания десяти наиболее частых букв русского алфавита. Эти буквы составляют слово СЕНОВАЛИТР.
Устойчивыми являются также частотные характеристики биграмм, триграмм и четырехграмм осмысленных текстов. Существуют специальные таблицы с указанием частоты биграмм некоторых алфавитов. По результатам исследований с помощью таких таблиц ученые определили наиболее часто встречаемые биграммы и триграммы для русского алфавита:
СТ, НО, ЕН, ТО, НА, ОВ, НИ, РА, ВО, КО, СТО, ЕНО, НОВ, ТОВ, ОВО, ОВА.
Из таблиц биграмм можно также легко извлечь информацию о сочетаемости букв, т.е. о предпочтительных связях букв друг с другом.
Результатом таких исследований является таблица, в которой слева и справа от каждой буквы расположены наиболее предпочтительные «соседи» (в порядке убывания частоты соответствующих биграмм). В таких таблицах обычно указывается также доля гласных и согласных букв (в процентах), предшествующих (или следующих за) данной букве.
| Г | С | Слева | Справа | Г | С | |
|---|---|---|---|---|---|---|
| 3 | 97 | л, д, к, т, в, р, н | А | л, н, с, т, р, в, к, м | 12 | 88 |
| 80 | 20 | я, е, у, и, а, о | Б | о, ы, е, а, р, у | 81 | 19 |
| 68 | 32 | я, т, а, е, и, о | В | о, а, и, ы, с, н, л, р | 60 | 40 |
| 78 | 22 | р, у, а, и, е, о | Г | о, а, р, л, и, в | 69 | 31 |
| 72 | 28 | р, я, у, а, и, е, о | Д | е, а, и, о, н, у, р, в | 68 | 32 |
| 19 | 81 | м, и, л, д, т, р, н | Е | н, т, р, с, л, в, м, и | 12 | 88 |
| 83 | 17 | р, е, и, а, у, о | Ж | е, и, д, а, н | 71 | 29 |
| 89 | 11 | о, е, а, и | З | а, н, в, о, м, д | 51 | 49 |
| 27 | 73 | р, т, м, и, о, л, н | И | с, н, в, и, е, м, к, з | 25 | 75 |
| 55 | 45 | ь, в, е, о, а, и, с | К | о, а, и, р, у, т, л, е | 73 | 27 |
| 77 | 23 | г, в, ы, и, е, о, а | Л | и, е, о, а, ь, я, ю, у | 75 | 25 |
| 80 | 20 | я, ы, а, и, е, о | М | и, е, о, у, а, н, п, ы | 73 | 27 |
| 55 | 45 | д, ь, н, о | Н | о, а, и, е, ы, н, у | 80 | 20 |
| 11 | 89 | р, п, к, в, т, н | О | в, с, т, р, и, д, н, м | 15 | 85 |
| 65 | 35 | в, с, у, а, и, е, о | П | о, р, е, а, у, и, л | 68 | 32 |
| 55 | 45 | и, к, т, а, п, о, е | Р | а, е, о, и, у, я, ы, н | 80 | 20 |
| 69 | 31 | с, т, в, а, е, и, о | С | т, к, о, я, е, ь, с, н | 32 | 68 |
| 57 | 43 | ч, у, и, а, е, о, с | Т | о, а, е, и, ь, в, р, с | 63 | 37 |
| 15 | 85 | п, т, к, д, н, м, р | У | т, п, с, д, н, ю, ж | 16 | 84 |
| 70 | 30 | н, а, е, о, и | Ф | и, е, о, а, е, о, а | 81 | 19 |
| 90 | 10 | у, е, о, а, ы, и | Х | о, и, с, н, в, п, р | 43 | 57 |
| 69 | 31 | е, ю, н, а, и | Ц | и, е, а, ы | 93 | 7 |
| 82 | 18 | е, а, у, и, о | Ч | е, и, т, н | 66 | 34 |
| 67 | 33 | ь, у, ы, е, о, а, и, в | Ш | е, и, н, а, о, л | 68 | 32 |
| 84 | 16 | е, б, а, я, ю | Щ | е, и, а | 97 | 3 |
| 100 | м, р, т, с, б, в, н | Ы | л, х, е, м, и, в, с, н | 56 | 44 | |
| 100 | н, с, т, л | Ь | н, к, в, п, с, е, о, и | 24 | 76 | |
| 14 | 86 | с, ы, м, л, д, т,, р, н | Э | н, т, р, с, к | 100 | |
| 58 | 42 | ь, о, а, и, л, у | Ю | д, т, щ, ц, н, п | 11 | 89 |
| 43 | 57 | о, н, р, л, а, и, с | Я | в, с, т, п, д, к, м, л | 16 | 84 |
Пример: Проведем анализ текста следующего содержания
«СОКРАТ из Афин (469–399 до н.э.) – знаменитый античный философ, учитель Платона, воплощенный идеал истинного мудреца в исторической памяти человечества. С именем Сократа связано первое фундаментальное деление истории античной философии на до- и после-Сократовскую («Досократики»), отражающее интерес ранних философов VI–V вв. к натурфилософии, а последующего поколения софистов V в. – к этико-политическим темам, главная из которых – воспитание добродетельного человека и гражданина. Сократу был близок софистическому движению. Учение Сократа было устным; все свободное время он проводил в беседах с приезжими софистами и местными гражданами, политиками и обывателями, друзьями и незнакомыми на темы, ставшими традиционными для софистической практики: что есть добро и что – зло, что прекрасно, а что безобразно, что добродетель и что порок, можно ли научиться быть хорошим и как приобретается знание. Об этих беседах мы знаем в основном благодаря ученикам Сократа – Ксенофонту и Платону. Кроме их сочинений, имеются также фрагменты и свидетельства о содержании «сократических диалогов» других сократиков, пародийное изображение Сократа в комедии Аристофана Облака и ряд замечаний о Сократе у Аристотеля. Проблема достоверности изображения личности Сократа в сохранившихся произведениях – ключевой вопрос всех исследований о нем.»
Электронная версия издания:
О. Н. Ляшевская, С. А. Шаров, Частотный словарь современного русского языка (на материалах Национального корпуса русского языка). М.: Азбуковник, 2009.
Частотность букв русского алфавита
| Буква | Абс. частота | Ранг | |
| 1 | а | 40487008 | 3 |
| 2 | б | 8051767 | 21 |
| 3 | в | 22930719 | 9 |
| 4 | г | 8564640 | 19 |
| 5 | д | 15052118 | 13 |
| 6 | е | 42691213 | 2 |
| 7 | ё | 184928 | 33 |
| 8 | ж | 4746916 | 25 |
| 9 | з | 8329904 | 20 |
| 10 | и | 37153142 | 4 |
| 11 | й | 6106262 | 23 |
| 12 | к | 17653469 | 11 |
| 13 | л | 22230174 | 10 |
| 14 | м | 16203060 | 12 |
| 15 | н | 33838881 | 5 |
| 16 | о | 55414481 | 1 |
| 17 | п | 14201572 | 14 |
| 18 | р | 23916825 | 8 |
| 19 | с | 27627040 | 7 |
| 20 | т | 31620970 | 6 |
| 21 | у | 13245712 | 15 |
| 22 | ф | 1335747 | 31 |
| 23 | х | 4904176 | 24 |
| 24 | ц | 2438807 | 28 |
| 25 | ч | 7300193 | 22 |
| 26 | ш | 3678738 | 26 |
| 27 | щ | 1822476 | 29 |
| 28 | ъ | 185452 | 32 |
| 29 | ы | 9595941 | 17 |
| 30 | ь | 8784613 | 18 |
| 31 | э | 1610107 | 30 |
| 32 | ю | 3220715 | 27 |
| 33 | я | 10139085 | 16 |
Сайт создан при финансовой поддержке Федерального агентства по образованию в рамках Федеральной целевой программы «Русский язык» (Госконтракт П66).
Статистика языка
Александр Чедович Пиперски
Развитие компьютеров привело к созданию больших собраний оцифрованных текстов на разных языках — так называемых лингвистических корпусов. Эти корпуса можно обрабатывать методами математической статистики. Математические модели, порой неожиданно простые, но эффективные, позволяют компьютерным лингвистам предложить человечеству и конкретному пользователю решение задач, связанных с автоматической обработкой естественного языка: распознавание речи, определение языка текста и машинный перевод, классификация текстов по темам, извлечение знаний из текста, выделение ключевых слов, анализ тональности текста (т. е. выяснение, содержится ли в нём положительная или отрицательная оценка), обнаружение спама, создание чат-ботов и т. д.
Рассмотрим две задачи — автоматическое определение языка текста и исправление опечаток, хорошие решения которых основаны на анализе частотности отдельных букв и слов, а также их сочетаний в реальных текстах. Удивительно, но такой подход позволяет решать эти задачи, не обладая знаниями ни о грамматических правилах языков, ни о смыслах анализируемых текстов.
Определение языка текста. Предположим, что компьютер получил задание определить, на каком языке написан такой текст:
Эта болгарская фраза означает «При том, что математика — строгая наука, она имеет и эстетическую сторону». Компьютер не владеет языками, но у него есть список языков, к одному из которых надо отнести этот текст. Будем считать, что круг кандидатов не слишком широк: английский, белорусский, болгарский, немецкий, русский, украинский, французский языки.
Самая простая идея, которая приходит в голову, — определять язык по алфавиту. В нашем случае это кириллица, поэтому сразу можно отбросить английский, немецкий и французский языки. Но этот метод не решит задачу полностью, например, он плохо справляется с русским и болгарским языками: болгарский алфавит — часть русского (в болгарском нет букв Ё, Ы, Э), так что любой болгарский текст можно принять за русский. Соотношение русского и украинского алфавитов сложнее, ни один не является частью другого: в украинском нет буквы Ъ, зато есть буквы для обозначения гласных звуков Є, І, Ї и согласного Ґ. Но все буквы данной фразы в нём присутствуют. В белорусском нет И (вместо неё используется буква І), поэтому он не подходит. Итак, алфавитный подход с задачей не справляется: осталось три языка-кандидата.
Наличие лингвистических корпусов позволяет анализировать языки, находить характеристики, которые их различают. В частности, «паспортом» языка может служить набор частот, с которыми в среднем встречаются буквы в этом языке.
На частотность букв обратили внимание ещё в докомпьютерную эпоху. Например, в телеграфной азбуке Морзе, возникшей в первой половине XIX века, наиболее часто используемым буквам ставили в соответствие более короткие сочетания точек и тире. Так, самые частые в английском языке буквы E и T кодируются односимвольно — точкой и тире соответственно. Эти буквы можно встретить и в начале верхнего ряда стандартной английской раскладки клавиатуры, унаследованной от пишущих машинок, — QWERTY. А в немецкой раскладке привычный глазу ряд заменён на QWERTZ — буква Y в немецком языке встречается существенно реже, чем Z, и сослана на периферию. Ещё один пример: в криптографии простые шифры на основе замены букв утратили значение после того, как были изучены частотные характеристики языков. Естественно, в XIX веке подсчёты частотности выполнялись вручную. Теперь же, с появлением лингвистических корпусов, частоты букв или слов можно посчитать на компьютере, причём эти данные будут более точными, объективными.
Если условиться, что русский алфавит состоит из 33 букв и пробела, то окажется, что самый частый символ — это пробел (14,46%), дальше следуют гласные О (9,42%), Е (7,33%), И (6,72%), А (6,52%) и согласные Н (5,83%), Т (5,56%). А реже всего встречаются буквы Ф (0,27%), Ъ (0,03%) и Ё (0,01%). Конечно, в каждом конкретном тексте частоты могут отличаться от приведённых, но эти отклонения будут несущественными.
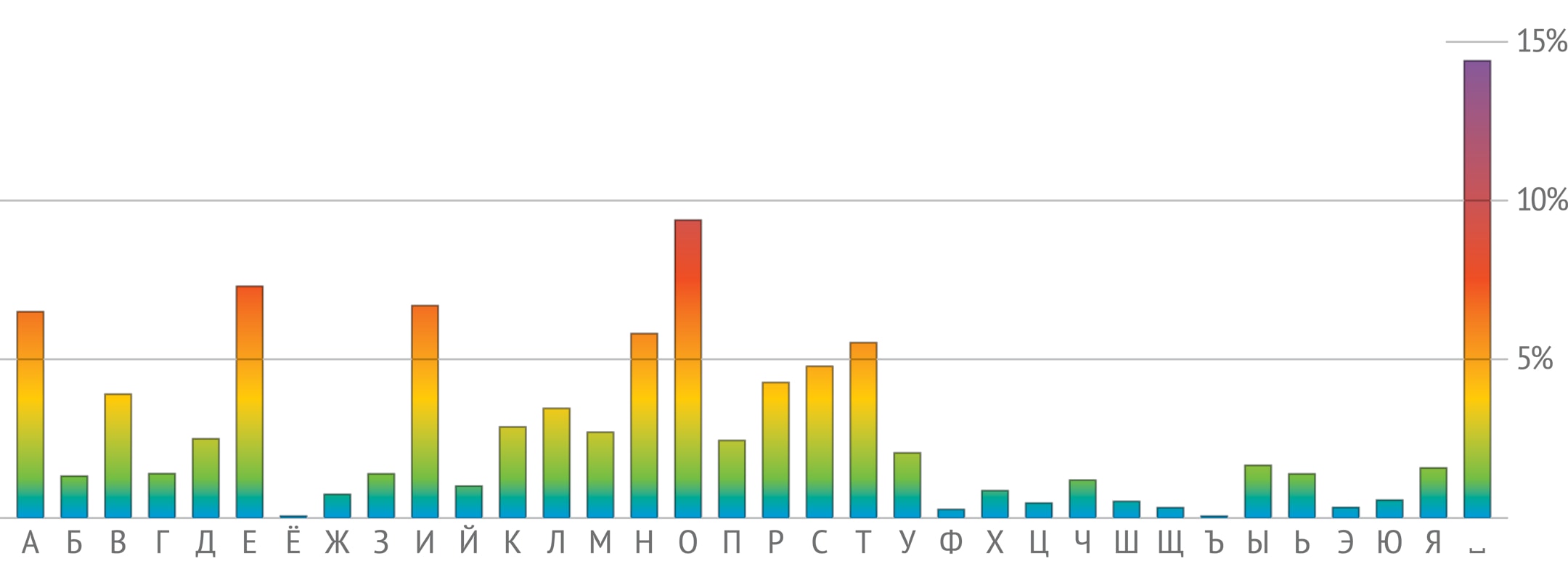
А вот в болгарском языке частоты букв будут другими. Первыми после пробела идут те же четыре гласные, что и в русском, но в обратном порядке: А, И, Е, О. Буква Ъ в русском языке — редкость, а в болгарском употребляется в разы чаще: она обозначает особый гласный звук типа краткого «а» и встречается даже в самом слове български. Последней по частотности буквой является Ь. Всё это показывает, что частотность букв действительно является индивидуальной характеристикой языка.
В компьютерном анализе (например, при определении языка) текст — это последовательность букв. В простейшей модели принимается, что каждая буква в этой последовательности появляется независимо от предыдущих, т. е. текст рассматривается как цепь независимых случайных событий: «прочитав» несколько букв, читатель не знает, что ждёт его дальше. Вследствие независимости вероятность встретить данную последовательность букв в выбранном языке равна произведению вероятностей (частот) появления букв в этом языке.
Зная частотности букв для каждого из трёх языков-претендентов, можно найти вероятность появления всей фразы:

Получается, что вероятность случайного появления этой фразы в болгарском языке в 300 раз больше, чем в русском, и в 300,000 раз больше, чем в украинском. Если о происхождении фразы нет априорной информации, то языки-кандидаты считаются равноправными. Это позволяет сравнивать вероятности появления фразы в разных языках, представив их более привычно, в процентах:
болгарский — 99,65%, русский — 0,3497%, украинский — 0,0003%.
Следовательно, выбрав вариант с максимальной вероятностью, в данном примере получим правильный ответ: фраза написана по-болгарски. Любопытно, что такой простой алгоритм неплохо сработал даже на тексте небольшой длины. Но так бывает не всегда. Например, для названия этой книги Математическая составляющая получается неожиданный результат:
болгарский — 51,55%, русский — 40,75%, украинский — 7,7%.
Симпатия этого алгоритма к болгарскому языку объяснима и носит общий характер: в нём меньше букв, чем в русском или украинском языках, а значит, частотность отдельной буквы будет в среднем чуть больше. Поэтому большинство нестандартных текстов алгоритм сочтёт болгарскими.
Точность определения языка текста можно повысить, если рассматривать не частоты букв по отдельности, а частоты комбинаций символов некоторой длины. Дело в том, что, в отличие от применённой выше простейшей модели, буквы в реальном тексте не независимы: на самом деле каждая буква зависит от предшествующих, по крайней мере — от предыдущей. Так, по правилам русского языка после Ъ могут идти только буквы Е, Ё, Ю или Я. В болгарском после Ъ можно встретить и букву Л, причём это в 10 раз вероятнее, чем встреча с Е, Ю и Я, вместе взятыми. А в украинском И почти не используется после пробела — значит, наша первая фраза со словами има и едва ли может быть украинской.
Эту идею академик Андрей Андреевич Марков (1856—1922) воплотил в математической модели, которая в его честь получила название «цепь Маркова». Он изучил распределение гласных и согласных в последовательности из 20,000 букв в романе «Евгений Онегин» (первая глава и начало второй). Основной вывод гласил: «Мы видим, что вероятность букве быть гласной значительно изменяется, в зависимости от того, предшествует ей гласная или согласная». Подсчёты А. А. Маркова показали, что общая доля гласных — 43,2%, но вероятность встретить гласную после гласной уменьшается до 12,8%, а после согласной — возрастает до 66,3%.

Получается, что в реальном тексте имеем дело не с вероятностями независимых случайных событий, а с условными вероятностями последовательно происходящих событий. В марковской модели будущее зависит от настоящего, а вот прошлое можно не анализировать: его влияние заложено в настоящем. Житейский пример: предсказывая погоду на завтра, можно ориентироваться на сегодняшнюю. Зимняя гроза — редкое явление, так что если сегодня гроза, то завтрашний день может оказаться и солнечным, и дождливым, но вряд ли выпадет снег. С другой стороны, если сегодня идёт снег, то увидеть завтра грозу — маловероятно.
Марковские цепи как математический инструмент можно использовать для анализа распределения не только гласных и согласных в данном языке, но и для всех пар букв алфавита. Зависимость буквы от предшествующей заметить несложно. Например, в русском языке среди пар, начинающихся с буквы З, наиболее вероятны сочетания ЗА (29,67%), ЗН (10,18%), З⎵ (пробел после З; 8,36%), а после буквы А те же символы А, Н, ⎵ дают совсем другие результаты: АА (0,03%), АН (9,56%), А⎵ (20,36%).
Для решения задачи определения языка текста можно сравнивать частотные характеристики пар из одинаковых символов в разных языках. Например, тройки лидеров среди пар, начинающихся с буквы З: в русских текстах — ЗА, ЗН, З⎵; в украинских — ЗА, З⎵, ЗН; в болгарских — ЗА, ЗИ, ЗВ.
Зная частоты всевозможных пар, можно в каждом из языков-кандидатов найти вероятность в марковской модели словосочетания Математическая составляющая, которое рассматривается как последовательность пар: ⎵ М (буква М является началом слова), МА, АТ, ТЕ, ЕМ и т. д. Вероятность всего словосочетания находится как произведение вероятностей этих пар. Результаты (округлённые) дают ответ на вопрос, где могла появиться такая книга:
болгарский — 0,06%, русский — 99,94%, украинский — 0,00003%.
А для фразы, с которой начался разговор (При все че математиката…), степень уверенности у марковской модели почти абсолютная: вероятность, что фраза написана по‐болгарски, равна 99,99991%!
Частотность последовательностей из двух (а лучше даже трёх) букв — очень точная характеристика языка. Приведённый метод — основа всех применяемых определителей языка, самый известный — модуль в Google Translate. Получается, что для решения этой лингвистической задачи не требуется знание языков, работает чистая статистика.
Исправление опечаток. Текстовые редакторы и смартфоны решают эту задачу методами, сходными с использовавшимися в задаче определения языка. Только теперь сравниваются частоты не букв, а слов и их последовательностей в выбранном языке.
Предположим, что пользователь ввёл фразу:
а задача компьютера — найти и исправить в ней опечатки. Человеку сразу понятно, что опечатка допущена в слове руква, а должно быть написано слово рука. Попробуем научить этому и компьютер, используя гигантский лингвистический корпус русскоязычных текстов общей длиной 16 миллиардов слов.
На первом этапе отыщем подозрительные слова: такие слова, которые либо отсутствуют в корпусе, либо встречаются там очень редко, скажем, для определённости — не более 100 раз (причиной возникновения в корпусе таких слов могут быть опечатки). А слова, которые встречаются более 100 раз, составляют словарь.
Вот сведения о частотах наших четырёх слов в корпусе: его — 46,643,493, руква — 50, немного — 3,475,296, болит — 203,993. По принятой договорённости алгоритм решает, что в слове руква допущена опечатка.
На втором этапе определим набор слов, одно из которых, возможно, хотел ввести пользователь. Очевидно, что эти слова должны быть похожими, близкими в каком-то смысле к слову руква: вряд ли человек хотел напечатать локоть, а получилась руква.
Для измерения близости слов в лингвистике обычно используется расстояние Дамерау —Левенштейна (названное в честь американского лингвиста и российского математика). Это расстояние равно минимальному числу «шагов», необходимых для превращения одного слова в другое. Такими шагами являются типовые, стандартные ошибки при наборе текста: замена одной буквы на другую, добавление или удаление буквы, перестановка соседних букв.
Например, расстояние между словами собака и кошка равно 3: замена с на к (получится кобака); замена б на ш (кошака); удаление первой а (кошка). Есть и другой путь длины 3: собака → соака → сошка → кошка. Но осуществить превращение меньше чем за 3 шага не удастся.
Такое расстояние между словами обладает всеми привычными свойствами расстояния между точками на плоскости: неотрицательность, симметричность (расстояние от собака до кошка равно расстоянию от кошка до собака), справедливо неравенство треугольника (см. «Далёкое близкое» ). Теперь можно формализовать ощущение, что слово руква легко получается из слова рука, но не из слова локоть: расстояние Дамерау —Левенштейна от рука до руква равно 1, а от локоть до руква — 5.
Опечаток в одном слове обычно немного, чаще всего одна. Найдём в словаре все слова, которые отстоят от подозрительного слова руква на расстояние 1. Слов-кандидатов не так много: рука (удаление в), рукав (перестановка а и в), буква (замена р на б) и рукава (добавление а). На этом можно остановиться и предложить пользователю список кандидатов — пусть выбирает сам. Именно так работает, например, проверка орфографии в Microsoft Word.
Но компьютер может пойти дальше и попробовать исправить опечатку, т. е. выбрать самого вероятного кандидата и предложить его пользователю (так поступает Google Docs), а может и сам подставить его в предложение (так обычно работают модули в смартфонах, «помогающие» набирать текст). Этот выбор единственного кандидата — следующий этап алгоритма, который можно реализовывать по-разному.
Простейшее, но неплохо работающее решение — выбрать самое частотное слово. Частоты слов-кандидатов в корпусе таковы: рука — 350,883, рукава — 126,817, буква — 107,262, рукав — 66,094. Как видно, в примере Его руква немного болит такой автоматический выбор совпадает с человеческим.
Здесь написана неправильная руква и У меня руква порвался
простейшее решение — заменить руква на рука — будет ошибочным. Чтобы алгоритм работал более «разумно», надо каким-то образом учитывать слова в контексте фразы. И здесь на помощь снова приходят марковские цепи.
Воспользуемся идеей, которая применялась в анализе по буквам, и попробуем предсказать следующее слово по последнему из виденных. Например, слово неправильная встречается в корпусе 50,267 раз; пары неправильная рукава и неправильная рукав в корпусе отсутствуют, неправильная рука встречается 4 раза, неправильная буква — 53 раза. На примере фразы Здесь написана неправильная руква видно, что метод выбора самой частотной пары соседних слов более эффективный, чем простейший алгоритм.
Дальнейшее улучшение алгоритма состоит в том, что учитываются и слово, идущее перед подозрительным словом, и слово, идущее после него. Определяются частоты обеих пар, найденные вероятности перемножаются. На примере фразы У меня руква порвался даже без статистических данных видно, что после сравнения произведений вероятностей пар выбор наибольшего выглядит достоверным решением:
Получается хорошо работающее исправление опечаток.
Разумеется, и этот алгоритм можно и нужно совершенствовать. Во‐первых, вероятности одношаговых опечаток отличаются: например, перестановка соседних букв в слове значительно вероятнее, чем замена буквы на удалённую от неё на клавиатуре (скажем, заменить б на р не так-то просто). Во‐вторых, можно встретиться с правильным, имеющим смысл словосочетанием, которое отсутствует в корпусе, и тогда произведение вероятностей будет равно нулю (пример: словосочетание> работающее исправление, которое мы использовали в конце предыдущего абзаца, в корпусе пока отсутствует). В‐третьих, рассмотренный вариант марковской цепи связывает слово только с ближайшими соседями, хотя в языке встречаются зависимости и на далёких расстояниях. Например, во фразе Руква у рубашки, которую Вася купил в аэропорту, оказались слишком короткими, выбирая на замену рукав или рукава, придётся опираться не на соседние, а на далёкие слова оказались и короткими. В‐четвёртых, сделав опечатки, можно получить фразу со словами из словаря, но ошибочную: например, У меня лукав порвался. Алгоритм такую фразу ни в чём не заподозрит. Впрочем, усложнение алгоритма позволяет справиться с подобными затруднениями.
Компьютерная лингвистика. Лингвистические корпуса — фундамент компьютерной лингвистики, неисчерпаемый источник сведений о языке. Их анализируют и профессионалы — лингвисты и компьютерные специалисты, и начинающие исследователи. Даже школьник может самостоятельно написать программу для поиска и проверки закономерностей в языковых массивах.
Самый известный ресурс для русского языка — это
Понятно, что частота отдельных слов и их сочетаний существенно зависит от набора текстов, включённых в корпус. У корпуса художественных текстов и корпуса текстов новостных — разный «словарный запас». Универсального, правильного корпуса для языка не существует, но надо научиться даже из отдельных, так или иначе «окрашенных» корпусов извлекать общие свойства, черты, особенности данного языка. Это желание вызывает в памяти восклицание основателя палеонтологии Жоржа Кювье: «Дайте мне одну кость, и я восстановлю животное!». По сути — это те задачи, из которых и родилась математическая статистика: как получить представление о ненаблюдаемом целом по некоторой выборке. И для их решения были созданы методы, более продвинутые, чем простой подсчёт частот.
Один из приёмов — усреднение, согласование значений частот по разным фрагментам корпуса, чтобы уменьшить влияние отдельных текстов. Например, частотность слова якорь в текстах НКРЯ, распределённых по десятилетиям, с 1970 года до наших дней, выглядит странно: 1970‐е — встречается 160 раз на миллион; 1980‐е — 6,8; 1990‐е — 8,4; 2000‐е — 6,6; 2010‐е — 6,7. Причина аномалии — включённая в НКРЯ «Книга о якорях», изданная в 1973 году. В ней одной слово якорь встречается 1769 раз, а во всём корпусе — только 2896. Полученная простым подсчётом частотность слова якорь по всему массиву — 21,9 на миллион — явно завышенная. Но если упорядочить значения частот по десятилетиям и взять число из середины списка (медиану), то получится более реальный результат: 6,8 на миллион. Можно учитывать и дисперсию, т. е. оценивать разбросанность значений: как часто и на сколько они отклоняются от среднего значения. Такой метод применял ещё А. А. Марков, работая с текстом «Евгения Онегина»: он проверял устойчивость, независимость своих результатов от способов подсчёта. Более сложные методы используются для предсказания «настоящих», истинных частот сочетаний слов: надо уметь отличать те, что в корпусе не встретились, но в принципе вполне возможны, от тех, что не встретились, потому что практически невозможны.
В заключение отметим, что автоматическая обработка языка начала активно развиваться в 1950‐е годы. В частности, первое время машинный перевод основывался на созданных вручную правилах, предписывавших, как именно переводить то или иное словосочетание при определённых условиях. Постепенно выяснилось, что сочинение правил требует огромных затрат человеческого труда, а работают они всё равно плохо.
Поэтому в конце 1980‐х годов на первый план в автоматической обработке естественного языка вышел статистический подход: посмотрим, как похожие задачи решались до нас человеком, и найдём решение, комбинируя его из готовых частей. Это стало возможным после появления лингвистических корпусов. Методы, рассмотренные нами на примерах, прежде всего частотность букв, слов и сочетаний, стали основой решения задач компьютерной лингвистики, перечисленных в начале статьи. Интересно, но временами создаётся впечатление, что алгоритмы и программы, основанные на статистическом подходе, в какой‐то мере освоили язык.
Например, эффективность применения марковских цепей неявно связана с грамматикой и структурой языка. В примере со словосочетанием Математическая составляющая при выборе одного из трёх языков помогла, в частности, высокая частотность сочетания ая в русском языке. Дело в том, что в русском языке в женском роде встречается окончание ‐ая, причём часто, а в болгарском и украинском в такой форме было бы просто ‐а.
В XXI веке математика предложила новые подходы к автоматической обработке языка. Бурное развитие искусственных нейронных сетей, обучаемых на огромных массивах входных данных, дало возможность решать самые разные задачи компьютерной лингвистики. А принципы работы нейронных сетей ещё больше приближают компьютер к тому, что можно назвать пониманием естественных языков. На данном этапе компьютерная лингвистика всё больше превращается в одну из разновидностей машинного обучения. Но если мы хотим разобраться с тем, что же происходит при обработке текстов искусственными нейронными сетями, нужен именно лингвистический взгляд. Лингвистика как наука необходима и для более полного использования возможностей уже существующих инструментов, и для построения новых математических моделей.
Алфавиты популярных языков мира
Алфавиты и системы письма самых известных и распространенных языков мира
Алфавит
Алфавит (др.-греч. ἀλφάβητος), — форма письменности, основанная на стандартном наборе знаков.
В алфавите отдельные знаки — буквы — обозначают фонемы языка, хотя однозначное соответствие звук ↔ буква наблюдается редко и имеет обыкновение утрачиваться в процессе развития устного языка.
Алфавит отличается от пиктографического (идеографического) письма, где знаки обозначают понятия (шумерская клинопись), и от морфемного и логографического письма, где знаки обозначают отдельные морфемы (китайское письмо) или слова.
Выделяются следующие разновидности алфавитов:
Использование знаков для отдельных фонем ведёт к значительному упрощению письма в результате сокращения количества используемых знаков. Также, порядок букв в алфавите является основой алфавитной сортировки.
Относительная сложность фонетических систем различных языков обуславливает наличие алфавитов неодинакового размера. Согласно Книге рекордов Гиннесса, больше всего букв — 74 — содержится в алфавите кхмерского языка, наименьшее — 12 (a, e, g, i, k, o, p, r, s, t, u, v) — в алфавите языка ротокас острова Бугенвиль (Папуа Новая Гвинея).
Самой древней буквой алфавита является буква «о», которая осталась неизменной в том же виде, в каком она была принята в финикийском алфавите (около 1300 года до н. э.). (Эта буква там обозначала согласный звук, но современная «о» произошла от неё).
Популярные алфавиты
Для каждого языка есть свой алфавит: английский, русский, китайский, испанский, немецкий, итальянский и другие. Английский язык принято считать международным, его изучают в учебных заведениях, его используют на международных конференциях, на нём ведут переговоры, он часто установлен по умолчанию в компьютерных программах и информационных системах.
Большая часть языков является ответвлением латинского языка, потому в областях науки и медицины бесспорным лидером является латынь.
Латинский алфавит также называют латиницей, латинский язык — латынью. Под фразой «писать на кириллице» понимается написание с использованием русских букв, под фразой «писать на латинице» в общем случае понимается написание с использованием английских букв.
Греческий
начало VIII века до н.э.
Латинский
около VII века до н.э.
ханаанейское письмо, финикийское письмо, греческий алфавит, этрусский алфавит
Английский
англо-саксонские руны, латинский алфавит
Русский
кириллица старославянского языка, произошедшая от греческого алфавита
Арабский
Фонетический алфавит
Фонетический алфавит — стандартизированный (для данного языка и/или организации) способ прочтения букв алфавита.
Применяется в радиосвязи при передаче написания сложных для восприятия на слух слов, сокращений, позывных, адресов электронной почты и тому подобное с целью уменьшения количества ошибок.
Международный фонетический алфавит
Международный фонетический алфавит (сокр. МФА, англ. International Phonetic Alphabet, сокр. IPA; фр. Alphabet phonétique international, сокр. API) — система знаков для записи транскрипции на основе латинского алфавита. Разработан и поддерживается Международной фонетической ассоциацией].
МФА используется преподавателями иностранных языков и студентами, лингвистами, логопедами, певцами, актёрами, лексикографами и переводчиками.
МФА разработан для отображения только тех качеств речи, которые являются различительными в устной речи: фонемы, интонация, разделение слов и слогов. Для передачи дополнительных особенностей речи (скрипа зубов, шепелявости, звуков, вызванных расщеплением нёба) используется дополнительный набор символов — расширения МФА.
Транскрипционный алфавит редактируется и модифицируется Международной фонетической ассоциацией. По состоянию на 2005 год МФА включает 107 символов-букв, 52 символа — диакритических знака и 4 символа — знака просодии.
Существует международный алфавит, разработанный в 1956-м году ИКАО. Это фонетический алфавит, принятый к использованию большинством международных организаций, в том числе и НАТО.
Основой для его создания послужил английский язык. Алфавит включает в себя буквы и цифры с фиксированным звучанием.
По сути, международный алфавит является набором звуковых сигналов. Алфавит применяется для радиопереговоров, передачи цифровых кодов, военных сигналов и идентификационных имён. Алфавит известен также как радио алфавит.
Технические алфавиты
Разработаны алфавиты (азбуки) технического характера, кодирующие буквы алфавитов в символы и обозначения. Они используются для обмена информации в средах, где написание или озвучивание обычных букв невозможны. Наиболее популярные азбуки:
Самые распространённые алфавиты мира
Самыми распространёнными системами письма являются: латинский алфавит, кириллица, арабское письмо и китайское.
Латинский алфавит используют в Европе (кроме некоторой части Балкан и части Восточной Европы), полностью в Северной и Южной Америках, в Африке (южнее Сахары), в странах Юго-Восточной Азии и Австралии.
Кириллица распространена во многих странах бывшего СССР, а также в Балканских странах и Монголии.
Япония, Корея, Малайзия, Сингапур и КНР используют в разных вариациях китайские иероглифы.
Арабская письменность распространена преимущественно в Северной Африке и Ближнем Востоке.
Словари древних языков
Греческий алфавит развился на основе финикийского и не связан с ранними греческими системами письма — линейным письмом Б и кипрским письмом.
Сохранились около 55 000 древних и средневековых греческих рукописей.
Каждая из букв финикийского алфавита называлась словом, начинавшимся с той же буквы; таким образом, первая буква носила название алеф («бык»), вторая буква — бет («дом»), третья буква — гимель («верблюд») и т. д.
Когда буквы были использованы для записи греческого языка, названия букв были лишь немного изменены для соответствия греческой фонологии. Так, алеф, бет, гимель стали альфа, бета, гамма, потеряв при этом всякий смысл. Позднее, когда некоторые буквы были добавлены в алфавит либо изменены, они получили осмысленные названия. К примеру, омикрон и омега значат, соответственно, «маленькое о» и «большое о».
Греческий алфавит послужил основой, на которой развилось множество алфавитов, широко распространившихся в Европе и на Ближнем Востоке и используемых в системах письменности большинства стран мира, в том числе латинский алфавит и кириллица.
Помимо использования для записи греческого языка, буквы греческого алфавита используются как международные знаки в математике и других науках; для наименования элементарных частиц, звёзд и других объектов.
Греческая письменность использовалась в некоторых языках Ближнего Востока, Причерноморья и близких областей — например, для записи бактрийского языка в Кушанском царстве и урумского (тюрко-ромейского) языка, относящегося к кыпчакско-половецкой подгруппе тюркской семьи языков, в тюрко-греческом языке Эпира и в караманлидском языке. Наряду с кириллицей и другими алфавитами, ранее использовался в славянских диалектах Греции и смежных земель; в гагаузском языке, арумынском языке.
Буквы греческого алфавита
Β β ϐ
Ε ε ϵ
Θ θ ϴ ϑ
Κ κ ϰ
Π π ϖ
Ρ ρ ϱ
Σ σ ς
Υ ϒ υ
Φ φ ϕ
Латинский алфавит
Латинский алфавит (латиница) — восходящая к греческому алфавиту буквенная письменность, возникшая в латинском языке в середине I тысячелетия до н. э. и впоследствии распространившаяся по всему миру.
Современный латинский алфавит, являющийся основой письменности большинства романских, германских, а также множества других языков, в своём базовом варианте состоит из 26 букв.
Буквы в разных языках называются по-разному.
Письменность на основе латинского алфавита используют все языки романской (кроме молдавского языка в ПМР и, в некоторых странах, сефардского языка), германской (кроме идиша), кельтской и балтийской групп, а также некоторые языки славянской, финно-угорской, тюркской, семитской и иранской групп, албанский, баскский языки, а также некоторые языки Индокитая (вьетнамский язык), Мьянмы, большинство языков Зондского архипелага и Филиппин, Африки (южнее Сахары), Америки, Австралии и Океании, а также искусственные языки (например, эсперанто).
Латинский алфавит начал формироваться предположительно в VIII веке до н. э. Древнейшие обнаруженные надписи датируются приблизительно VII веком до н. э. Согласно В. Истрину, ранние надписи носят переходный характер от западногреческого и этрусского к латинскому письму. Классический латинский алфавит окончательно сложился около I века до н. э. Направление письма в архаичных надписях могло быть как слева направо, так и справа налево. Засвидетельствованы также надписи бустрофедоном.
Существуют две гипотезы происхождения латинского алфавита. По одной гипотезе, латинский язык заимствовал алфавитное письмо из греческого напрямую, по другой — своеобразным посредником в этом оказался этрусский алфавит. В том и в другом случае основой латинского алфавита является западногреческий (южноиталийский) вариант греческого алфавита. Латинский алфавит обособился примерно в VII веке до н. э. и первоначально включал только 21 букву: A, B, C, D, E, F, Z, H, I, K, L, M, N, O, P, Q, R, S, T, V и X.
Архаичный латинский алфавит
В архаичном латинском алфавите буквы C (восходящая к архаичному наклонному начертанию греческой гаммы Γ), K (от греческой каппы Κ) и Q (от впоследствии исключённой из греческого алфавита буквы коппа Ϙ) использовались для обозначения звуков [k] и [g]; при этом K ставилась перед A; буква Q (иногда) ставилась перед V и O; а C ставилась всюду.
Классический латинский алфавит
Буква
Буква
Буква
Уже в новое время, около XVI века произошла дифференциация слоговых и неслоговых вариантов букв I и V (I/J и U/V). В итоге получился современный алфавит из 25 букв:
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Xx Yy Zz
Примерно в то же время, но только в северной Европе стал считаться отдельной буквой диграф VV, возникший в XI веке и использующийся в письме германских языков. С добавлением W алфавит достиг своего окончательного состава из 26 букв:
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz
Этот стандартный 26-буквенный алфавит зафиксирован Международной организацией по стандартизации (ISO) как «базовый латинский алфавит». Этот алфавит совпадает с современным английским алфавитом.
Однако, когда говорят об алфавите собственно латинского языка, а также романских языков, то W чаще всего не включают в состав букв (тогда латинский алфавит состоит из 25 букв).
В средние века в скандинавских и английском алфавитах использовалась руническая буква þ (название: thorn) для звука [θ] (как в современном английском thing), однако позднее она вышла из употребления. В настоящее время thorn используется только в исландском алфавите.
Все прочие добавочные знаки современных алфавитов, основанных на латинском, происходят от указанных выше 26 букв с добавлением диакритических знаков или в виде лигатур (так, немецкая буква ß, эсцет, происходит из готической лигатуры букв S и Z).
Современный латинский алфавит
классическое
русское
название буквы
латинское
название буквы
французское
название буквы
итальянское
название буквы
английское
название буквы
немецкое
название буквы
(doppia vu/доппья ву)
ī Graeca/и грайка
(igrec/игрек)
(i greca/и грека
либо ipsilon/ипсилон)
1. буквы j, k, w, x и y в итальянском языке используются в лишь некоторых иностранных именах собственных (Jaroslavl (Ярославль), Kennedy (Кеннеди), Texas (Техас) и т. п.) и заимствованных словах (итал. water — унитаз), но в алфавит не включены, и поэтому их названия приведены в скобках. В латинском языке же буква «w» используется в лишь некоторых иностранных именах собственных и научных названиях, но в алфавит не включена, и поэтому её название приведено в скобках. А буквы x», «y», «z» там стали называться «икс», «игрек», «зет» сравнительно недавно, поэтому их наиболее известные названия приведены в скобках.
2. В латинском языке же буква «w» используется в лишь некоторых иностранных именах собственных и научных названиях, но в алфавит не включена, и поэтому её название приведено в скобках.
3. А буквы x», «y», «z» там стали называтся «икс», «игрек», «зет» сравнительно недавно, поэтому их наиболее известные названия приведены в скобках.
Латинский алфавит как международный
В настоящее время латинский алфавит знаком почти всем умеющим читать людям Земли, поскольку изучается всеми школьниками либо на уроках математики, либо на уроках иностранного языка (не говоря уже о том, что для многих языков латинский алфавит является родным), поэтому он де-факто является «алфавитом международного общения». На латинском алфавите основано большинство искусственных языков, в частности, эсперанто, интерлингва, идо и другие.
Для всех языков с нелатинской письменностью существуют также системы записи латиницей (романизации) — даже если иностранец и не знает правильного чтения, ему гораздо легче иметь дело со знакомыми латинскими буквами, чем с «китайской грамотой». В ряде стран вспомогательное письмо латиницей стандартизировано и дети изучают его в школе (в Японии, Китае).
Запись латиницей в ряде случаев диктуется техническими трудностями: международные телеграммы всегда писались латиницей; в сети Интернет можно встретить запись русского языка латиницей из-за отсутствия поддержки кириллицы клиентской машиной (см. транслит; то же относится и к греческому языку).
С другой стороны, в текстах на нелатинском алфавите иностранные названия нередко оставляют латиницей из-за отсутствия общепринятого и легко узнаваемого написания в своей системе. Например, иногда в русском тексте японские названия пишут латиницей, хотя для японского языка существуют общепринятые правила транслитерации в кириллический алфавит.
Английский алфавит
Алфавит английского языка основан на латинском алфавите и состоит из 26 букв.
6 букв могут обозначать гласные звуки (монофтонги и дифтонги, самостоятельно или в составе диграфов): «A», «E», «I», «O», «U», «Y».
21 буква может обозначать согласные звуки: «B», «C», «D», «F», «G», «H», «J», «K», «L», «M», «N», «P», «Q», «R», «S», «T», «V», «W», «X», «Y», «Z».
Буква «Y» может обозначать как согласный, так и гласный звуки.
Буква «W» самостоятельно означает согласный звук, но используется и в составе диграфов, обозначающих гласные звуки. В британском произношении (англ. received pronunciation) то же верно и для буквы «R».
Буквы современного английского алфавита
Произношение
названия буквы (МФА)
Русская запись
названия буквы
haitch [heɪtʃ] в Ирландии
и часто в Австралии
[ɑr] в североамериканском
произношении
или в позиции перед гласным
Пишется es- в сочетаниях
типа es-hook
zee — американский вариант
В английском языке имеются следующие диграфы:
Диакритические знаки
Как только такие слова становятся натурализованными в английском, они обычно теряют диакритические знаки, как это произошло со старыми заимствованиями, к примеру, французским словом hôtel. В неформальном английском диакритика часто опускается в силу отсутствия букв с ней на клавиатуре, в то время как профессиональные копирайтеры и наборщики предпочитают её использовать. Те слова, что ещё воспринимаются как чужие, часто сохраняют диакритику. К примеру, единственное написание слова soupçon, найденное в английских словарях (Оксфордском и других) использует диакритический знак. Диакритические знаки чаще сохраняются тогда, когда при их отсутствии возможна путаница с другим словом (к примеру, résumé (или resumé [резюме] «резюме (для приема на работу)», а не resume [ризьюм] «возобновить») и, редко, даже добавляются (как в maté, от испанского yerba mate, но следуя примеру написания слова café, из французского).
Акут, гравис или диерезис могут быть поставлены над «e» в конце слова для обозначения того, что она произносится (saké).
В целом, диакритические знаки часто не используются даже в тех местах, где они могли бы позволить избежать путаницы.
Частота букв
Самой часто встречаемой буквой в английском языке является «E», самой редкой — «Z».
Список частот букв, используемых в английском языке
Буква
Русский алфавит
Русский алфавит (русская азбука) — алфавит русского языка, в нынешнем виде — с 33 буквами — существующий с 1918 года (буква Ё официально утверждена лишь с 1942 года: ранее считалось, что в русском алфавите 32 буквы, поскольку Е и Ё рассматривались как варианты одной и той же буквы).
В таблице приведены названия букв в соответствии с орфографией соответствующего времени.
начало XIX века
к 1860 году
1934 год
к 1940 году
к 1987 году
2006 год
Немецкий алфавит
Немецкий алфавит — алфавит на латинской основе, применяемый в письме на немецком языке.
Состоит из 26 пар латинских букв: A a, B b, C c, D d, E e, F f, G g, H h, I i, J j, K k, L l, M m, N n, O o, P p, Q q, R r, S s, T t, U u, V v, W w, X x, Y y, Z z. Помимо них, в немецком алфавите присутствуют три умляута (Ä ä, Ö ö, Ü ü) и лигатура ß. Последние подчиняются алфавитному порядку, то есть в словарях следуют сразу после A a, O o, U u и удвоенной ss, соответственно. В отдельных случаях применяются дополнительные варианты букв, но это характерно лишь для некоторых диалектов и, в частности, для слов иностранного происхождения, использующихся в немецком языке.
Ниже представлена таблица, в которой даны основные правила чтения и диктовки немецких букв.
Диктовка по DIN 5009
(немецкий телефонный алфавит)
Band, Tag
После i и j слышится как ja — Maria; ai — дифтонг /aɪ̯/ («ай»); ae — слышится ä; au — дифтонг /aʊ̯/; удвоенное aa может читаться долго — Haar («волосы»).
Hände, Ähre
Перед u — дифтонг /ɔʏ̯/ (оу).
Встречается в сочетании с другими буквами: с h образует буквосочетание ch, слышимое как /x/ или /ç/; ck — /k/; в chs — /ks/; sch — /щ/ tsch — /ч/; редко одна c слышится как /t͡s/ (перед e, i); в начале слов читается как /k/.
ausdenken
kennen, bekannt, See
ie — /i:/, oe — /ø:/; ei, ey, ai, ay — дифтонг /aɪ̯/.
Такой же звук даёт немецкая буква v.
gut, Genie, König
Часто h вообще не читается, например, между гласными и в конце слова — gehen
(разделяет две e, и в этом слове они читаются раздельно, а не как один долгий звук; «ходить»), weh («воспалённый, больной»).
bitten, Vieh
В ie — /i:/; ei, ai — /aɪ̯/.
jung, Journalist
В буквосочетании ck — /k/.
Flöte
Stimme
senden
offen, Kohl
В буквосочетании oe — /ø:/.
Österreich, zwölf, schön
pf — аффриката /p͡f/.
В сочетании qu — /kv/.
Drache
Samuel (до 1934 — Siegfried)
Bus, sehen
В sp и st — /ʃ/; sch — /ʃ/.
heiß
Стоит в середине или конце слова и читается как обычный звук /s/.
Platte
au — /aʊ̯/, eu, äu — /ɔʏ̯/.
Übung, küssen, Überhaupt
Даёт звукосочетание /ks/ — Max.
Ypsilon, Typ, Yacht
Zacharias (до 1934 — Zeppelin)
dreizehn
Первые источники немецкой письменности относятся ещё к древневерхненемецкому периоду развития немецкого языка или даже ранее. Практически до XII века существовала руническая письменность, которая позднее была полностью вытеснена латиницей. В XV—XVI веках популярностью пользовался шрифт швабахер (Schwabacher), входящий в группу готических шрифтов.
Готическим письмом немецкие буквы писались практически до начала XX века — в частности, возникшей в XVII—XVIII вв. фрактурой (Fraktur). С конца XIX века широкое распространение получает антиква, но официально она признаётся только после Ноябрьской революции в 1918 году. Антиква считалась более простым и легко воспринимаемым шрифтом, нежели ломаное готическое письмо. В 1920—30-е годы хождение получил шрифт Зюттерлина (Sütterlinschrift).
В мореплавании используется немецкая версия. Тем не менее, в настоящее время в авиации и военном деле используется международная версия фонетического алфавита, а не немецкая.
Французский алфавит
Во французском алфавите используются 26 пар латинских букв (строчные и прописные) и диакритические знаки.
Французское
название
буквы (МФА)
Французское
название
буквы (МФА)
Буквы с диакритикой
Буквы с диакритикой — это буквы особенного написания, с точками, штрихами, “шапочками” или другими элементами, такие как ù, à, ç, é, è, û, ë, â.
Французские буквы с диакритикой
Буквы с диакритикой (для многих из них варианты с прописной буквой редки или практически невозможны вне заголовков):
Замена букв с диакритикой на буквы без диакритики официально является орфографической ошибкой, но на практике диакритику над прописными буквами по техническим причинам часто опускают. Инициальные аббревиатуры пишутся без диакритики: CEE (Communauté Économique Européenne); графические сокращения её сохраняют: É.-U. (États-Unis).
При сортировке диакритические знаки не учитываются (за исключением слов, которые различаются только ими).
Лигатуры
Лигатуры: Ææ Œœ. Нередко по техническим причинам заменяются на две буквы: ae (или фонетическую запись é), oe.
Испанский алфавит
Испанский алфавит является модифицированным вариантом латинского алфавита, состоящим из 27 букв A, B, C, D, E, F, G, H, I, J, K, L, M, N, Ñ, O, P, Q, R, S, T, U, V, W, X, Y, Z.
Диграфы CH и LL обозначают отдельные звуки и до 1994 года они считались отдельными буквами и располагались в алфавите отдельно от C и L. Над гласными (A, E, I, O и U) может писаться ударение для обозначения ударного слога или иного смысла слова и трема над U для указания на раздельное прочтение.
Испанская орфография развивалась в течение почти 800 лет, начиная с эпохи Альфонса Мудрого, и была стандартизирована под руководством Испанской королевской академии. С момента публикации Орфографии кастильского языка (исп. Ortografía de la lengua castellana) в 1854 году испанская орфография пережила несколько незначительных изменений. Основными принципами испанской орфографии являются фонологический и этимологический, поэтому существует несколько букв, обозначающих одинаковые фонемы. Начиная с XVII века предлагались различные варианты реформы орфографии, которая создала бы однозначное соответствие между графемой и фонемой, но все они были отклонены. Фонетические расхождения между различными диалектами испанского языка делают невозможным создание чисто фонетической орфографии, которая бы адекватно отражала многообразие языка. Большинство современных предложений по реформированию правописания ограничиваются отменой букв-омофонов, которые сохраняются по этимологическим соображениям.