Регистры ассемблера: виды, назначение и особенности команд
Ячейки процессора, которые также называются регистры ассемблера, из-за управляющего ими низкоуровневого языка программирования представляют собой некий блок свободных элементов в памяти. Их характерной особенностью является сверхбыстрый доступ к памяти. Чаще всего применяются регистры во время выполнения команд процессора и для программиста недоступны. Например, во время выборки из имеющейся сверхбыстрой памяти следующей по номеру команды ее код в двоичной системе помещается в регистр.
Напрямую обратиться к регистру невозможно. Кроме того, имеется ряд доступных блоков памяти, однако обратиться к ним возможно только из оболочки операционной системы. К таковым относят управляющие сегментные регистры, а также теневые системы дескрипторов. Применяют в своей работе данные регистры исключительно девелоперы ОС.
 Вам будет интересно: Как записать гитару в FL Studio: простейшие методы
Вам будет интересно: Как записать гитару в FL Studio: простейшие методы
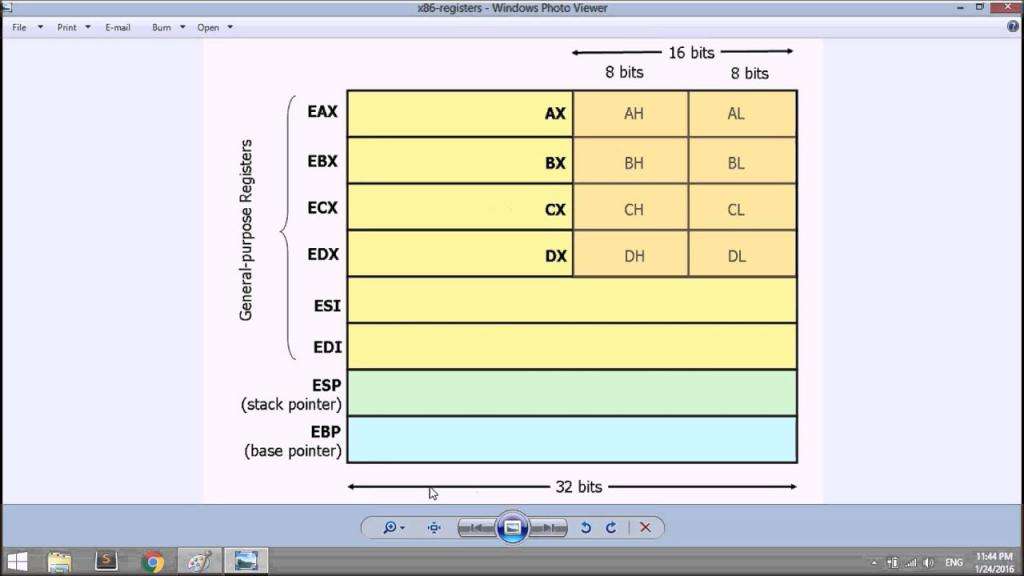
Виды регистров
Для различных нужд во время программирования применяются разные регистры Assembler. Используют их в зависимости от целей. К примеру, регистр счетчика применяется для организации как простых, так и вложенных циклов. Ниже перечислены основные типы регистров ассемблера:
 Вам будет интересно: Как сделать визитку в иллюстраторе своими силами
Вам будет интересно: Как сделать визитку в иллюстраторе своими силами
Фактически все регистры занимают в памяти 32 бита. То есть могут содержать числа от нуля до 4294967295. Некоторые из регистров разделены на несколько частей по 16 и 8 бит. Это позволяет управлять либо частью блока памяти, либо ячейкой целиком, записывая в нее только часть данных.

Регистры ассемблера получили название согласно выполняемым функциям:
Особенности использования регистров
Регистры общего назначения
Регистры указатели
Для работы со стеком в assembler разработчиками предусмотрено два вида регистра. Для доступа к ним осуществляется операция прибавления к указателю вершины абстрактного типа значений битности определенного типа данных, который был помещен в стек. Все расчеты проводятся вручную. Таким образом сохраняется большое количество данных и передается в подпрограммы – процедуры и массивы. Среди регистров указателей в ассемблере выделяют:
Регистры-индексы
Индексные блоки памяти требуются для расширенной индексации. Кроме того, они участвуют в работе некоторых арифметических операций и обработки байтовых строк – последовательности байт, содержащих произвольное значение. В assembler включено два регистра, которые отвечают за индексирование ESI и EDI. Опишем их:
Сегментные регистры
Являются первыми блоками в памяти. Называются текущими сегментами. Программному обеспечению разрешается распределять более четырех блоков памяти. Однако при этом обязательно занести адреса блоков в ячейки памяти между сегментными регистрами. Данный вид блоков памяти является строго специфичным, благодаря чему невозможно заполнять их отдельным видом данных. Порядок блоков регистров в памяти может меняться. Хранение сегментных регистров производится в произвольном порядке в случайных местах памяти.
Регистр указателя команд
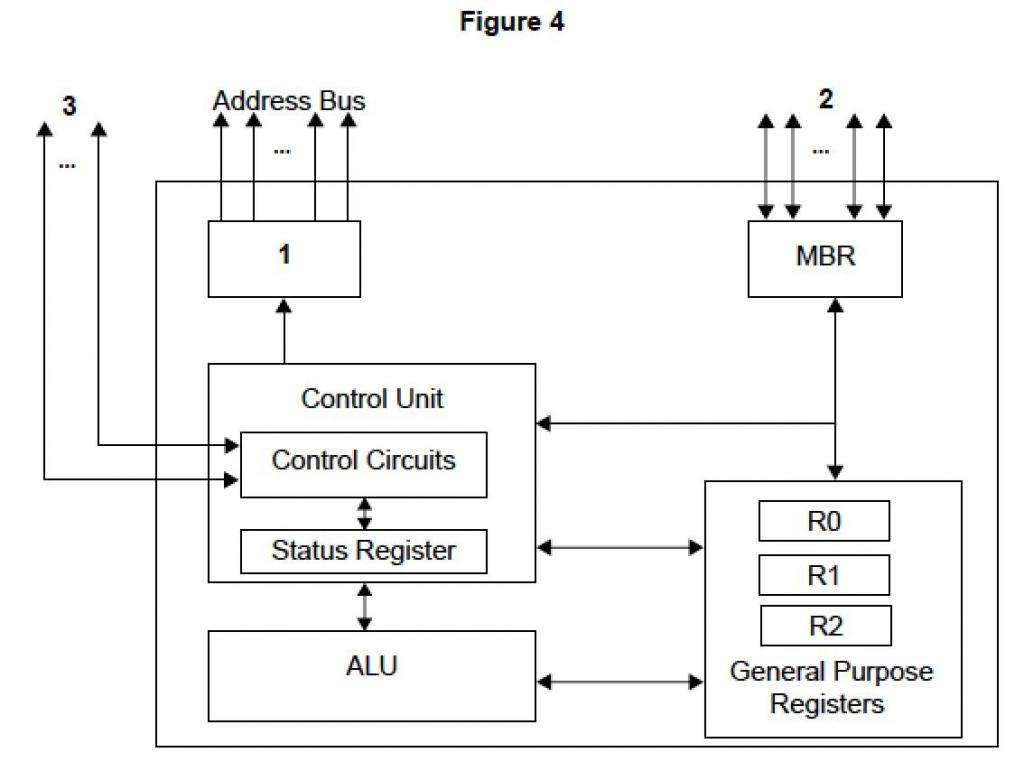
Данный вид относится к командным. С помощью данного указателя осуществляется вывод регистра ассемблера в листинг. Включает данные по поводу смещения на следующую команду относительно предыдущей. При разработке программного обеспечения практически не используется, однако требуется для просмотра листинга выполнения кода. Таким образом отслеживают ошибки.
Регистр флагов ассемблера
Отвечает за текущее состояние центрального процессора. Состоит из 16 бит, из которых могут быть заняты только 9. Заполнение данного блока памяти осуществляется после выполнения, пропуска или кода ошибки в результате предыдущей команды. Кроме того, часть битов используется процессором и может инициализироваться и удаляться посредством определенной системы команд. Таким образом осуществляется управление системой команд.
Работа с регистрами
Регистры, байты, биты
В этом уроке мы научимся работать напрямую с регистрами микроконтроллера. Зачем? Я думаю в первую очередь это нужно для того, чтобы понимать чужой код и переделывать его под себя, потому что прямая работа с регистрами в скетчах из Интернета встречается довольно часто. Начнём с того, что вспомним, где мы пишем код: Arduino IDE. Несмотря на большое количество не всегда оправданного негатива в сторону этой программы, она очень крутая. Помимо кучи встроенных инструментов и поддержки “репозиториев” от сторонних разработчиков, Arduino IDE позволяет нам программировать плату на разных языках программирования. Это некая условность, но по сути получается три языка:
Что такое регистр? Тут всё весьма просто: это сверхбыстрые блоки оперативной памяти объёмом 1 байт, находящиеся рядом с ядром МК и периферией. На стороне программы это обычные глобальные переменные, которые можно читать и изменять. В регистрах микроконтроллера хранятся “настройки” для различной его периферии: таймеры-счётчики, порты с пинами, АЦП, шина UART, I2C, SPI и прочее железо, встроенное в МК. Меняя регистр, мы даём практически прямую команду микроконтроллеру, что и как нужно сделать. Запись в регистр занимает 1 такт, то есть 0.0625 микросекунды (при частоте тактирования 16 МГц) – это ОЧЕНЬ быстро. Имена регистров фиксированные, полный перечень с подробным описанием можно найти в даташите на микроконтроллер (официальный даташит на ATmega328 – Arduino Nano/UNO/Mini). Работа с регистрами очень непростая, если вы не выучили их все наизусть, потому что названия у них обычно нечитаемые, аббревиатуры. Так называемые “Ардуиновские” функции собственно и занимаются тем, что работают с регистрами, оставляя нам удобную, понятную и читаемую функцию. Ничего сверхъестественного в этом нет. Зачем вообще работать с регистрами напрямую? Есть несколько больших преимуществ:
Но считать значение бита по его названию можно! Причём значение будет равно его номеру в регистре, считая справа. CS11 равен 1, WGM13 равен 4, ICNC1 равен 7 (см. таблицу выше). Думаю здесь всё понятно: есть регистр (байт), имеющий уникальное имя и состоящий из 8 бит, каждый бит также имеет уникальное имя, по которому можно получить номер этого бита в байте его регистра. Осталось понять, как этим всем пользоваться.
Запись/чтение регистра
Существует несколько способов установки битов в регистрах. Мы рассмотрим их все, чтобы столкнувшись с одним из них вы знали, что это вообще такое и как работает данная строчка кода. Абсолютно вся работа с регистрами заключается в установке нужных битов в нужном байте (в регистре) в состояние 0 или 1. Рекомендую прочитать урок по битовым операциям, в котором максимально подробно разобрано всё, что касается манипуляций с битами. Давайте вернёмся к регистру таймера, который я показывал выше, и попробуем его сконфигурировать. Первый способ, это явное задание всего байта сразу, со всеми единицами и нулями. Сделать это можно так:
Только на первый можно посмотреть и сразу понять, что где стоит. Чего не скажешь про остальные два. Очень часто в чужих скетчах встречается такая запись, и это не очень комфортно. Гораздо чаще бывает нужно “прицельно” изменить один бит в байте, и тут на помощь приходят логические (битовые) функции и макросы. Рассмотрим все варианты, во всех из них BYTE это байт-регистр, и BIT это номер бита, считая с правого края. То есть BIT это цифра от 0 до 7, либо название бита из даташита.
| Установка бита в 1 | Установка бита в 0 | Описание | ||
| BYTE |= (1 | BYTE &= (1 | Использование битового сдвига BYTE |= (2^BIT); | BYTE &= (2^BIT); | Используем 2 в степени (пример не рабочий!) |
| BYTE |= bit(BIT); | BYTE &= bit(BIT); | Используем ардуиновский макрос bit(), заменяющий сдвиг | ||
| BYTE |= _BV(BIT); | BYTE &= _BV(BIT); | Используем встроенную функцию _BV(), опять же аналог сдвига | ||
| sbi(BYTE, BIT); | cbi(BYTE, BIT); | Используем общепринятые макросы sbi и cbi | ||
| bitSet(BYTE, BIT); | bitClear(BYTE, BIT); | Используем ардуиновские функции bitSet() и bitClear() |
Можно ещё добавить вариант, где в одной строчке можно “прицельно” установить несколько битов:
Я думаю тут всё понятно, давайте теперь попробуем “прицельно” прочитать бит из регистра:
| Чтение бита | Описание |
| (BYTE >> BIT) & 1 | Вручную через сдвиг |
| bitRead(BYTE, BIT) | Ардуиновская макро-функция |
Два рассмотренных способа возвращают 0 или 1 в зависимости от состояния бита. Пример:
Ещё больше примеров работы с битами смотри в предыдущем уроке по битовым операциям.
16-бит регистры
Такую запись почему-то используют редко, возможно для совместимости с другими компиляторами. Чаще всего вы встретите вот такой вариант, в котором значения “склеиваются” через сдвиг:
Записывать нужно со старшего байта. Как только мы записываем младший байт (последний) – МК “защелкивает” оба регистра в память, соответственно если сначала записать младший – в старшем будет 0, и последующая запись старшего будет проигнорирована.
Правда о регистре символов, которую должны знать программисты
На конференции North Bay Python в 2018 году я делал доклад об именах пользователей. Информация из доклада по большей части была собрана мною за 12 лет поддержки django-registration. Этот опыт дал мне гораздо больше знаний, чем я планировал получить, о том, насколько сложными могут быть «простые» вещи.
В начале доклада я, правда, упомянул, что это не будет очередное разоблачение из серии «заблуждения по поводу Х, в которые верят программисты». Таких разоблачений можно найти сколько угодно. Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Поэтому в своём докладе я постарался как можно лучше объяснить некоторые проблемы и пояснить, как их решать – такой подход мне нравится гораздо больше. Одна из тем, которой я коснулся лишь вскользь (это был всего один слайд и пара упоминаний на других слайдах) – это сложности, которые могут быть связаны с регистром символов. Для задачи, которую я обсуждал – сравнение идентификаторов без учёта регистра – есть официальный Правильный Ответ™, и в докладе я дал лучшее из известных мне решений, использующее только стандартную библиотеку Python.
Однако я кратко упомянул о более глубоких сложностях с регистром символов в Unicode, и хочу посвятить некоторое время описанию подробностей. Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
И ещё одно: в Unicode полно терминологии. В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
Регистров бывает больше двух
Носители европейских языков привыкли к тому, что в их языках регистр символов используется для обозначения конкретных вещей. К примеру, в английском [и русском] языках мы обычно начинаем предложения с буквы в верхнем регистре, а продолжаем чаще всего буквами в нижнем регистре. Также имена собственные начинаются с букв в верхнем регистре, и многие акронимы и аббревиатуры записываются в верхнем регистре.
И мы обычно считаем, что регистров существует всего два. Есть буква «А», и есть буква «а». Одна в верхнем, другая в нижнем регистре – не правда ли?
Однако в Unicode есть три регистра. Есть верхний, есть нижний, и есть титульный регистр [titlecase]. В английском языке так записываются названия. Например, «Avengers: Infinity War». Обычно для этого первая буква каждого слова просто пишется в верхнем регистре (и в зависимости от разных правил и стилей, некоторые слова, например, артикли, не пишутся с заглавных букв).
В стандарте Unicode дан такой пример символа в титульном регистре: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. Выглядит он так: Dz.
Подобные символы иногда требуются для обработки негативных последствий одного из ранних решений разработки стандарта Unicode: совместимости с существующими текстовыми кодировками в обе стороны. Для Unicode было бы удобнее составлять последовательности при помощи имеющихся у стандарта возможностей по комбинированию символов. Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа «é» есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Хотя кодовая позиция этого символа совпадает с его байтовым значением из latin-1, полагаться на это не стоит. Вряд ли кодирование символов в Unicode сохранит эти позиции. К примеру, в UTF-8 кодовая позиция U+00E9 записана в виде байтовой последовательности 0xc3 0xa9.
И, конечно, в уже существующих кодировках есть символы, которым требовалось особое обхождение при использовании титульного регистра, из-за чего они были включены в Unicode «как есть». Если хотите посмотреть на них, поищите в своей любимой базе Unicode символы из категории Lt («Letter, titlecase»).
Есть несколько способов определить регистр
Если вы работаете с ограниченным подмножеством символов (конкретно, с буквами), то вам может хватить и 1-го определения. Если ваш репертуар шире – в него входят похожие на буквы символы, не являющиеся буквами, вам может подойти 2-е определение. Его рекомендует и стандарт Unicode, §4.2:
Программистам, манипулирующим строками в Unicode, стоит работать с такими строковыми функциями, как isLowerCase (и её функциональным родственником toLowerCase), если они не работают со свойствами символов напрямую.
Упомянутая здесь функция определяется в §3.13 стандарта Unicode. Формально в 3-м определении используются функции isLowerCase и isUpperCase из §3.13, определяемые в терминах фиксированных позиций в toLowerCase и toUpperCase соответственно.
Если в вашем языке программирования есть функции для проверки или преобразования регистра строк или отдельных символов, стоит изучить, какие из упомянутых определений используются в реализации. Если вам интересно, то методы isupper() и islower() в Python используют 2-е определение.
Нельзя понять регистр символа по его внешнему виду или названию
По внешнему виду многих символов можно понять, в каком они регистре. К примеру, «А» находится в верхнем регистре. Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
На самом же деле она наследует свойство Lowercase, поэтому по определению №2 она находится в нижнем регистре, несмотря на то, что визуально напоминает заглавную Н, а в названии есть слово «CAPITAL».
У некоторых символов вообще нет регистра
Символ С имеет регистр тогда и только тогда, когда у С есть свойство Lowercase или Uppercase, или значение параметра General_Category равно Titlecase_Letter.
Значит, очень много символов из Unicode – на самом деле, большая их часть – регистра не имеет. Не имеют смысла вопросы об их регистре, а изменения регистра на них не действуют. Однако мы можем получить ответ на этот вопрос по определению №3.
Некоторые символы ведут себя так, будто у них несколько регистров
Из этого следует, что если вы используете определение №3, и задаёте вопрос, находится ли символ без регистра в верхнем или нижнем регистре, вы получите ответ «да».
В стандарте Unicode даётся пример (таблица 4-1, строка 7) символа U+02BD MODIFIER LETTER REVERSED COMMA (который выглядит так: ʽ). У него нет унаследованных свойств Lowercase или Uppercase, он не принадлежит к категории Lt, поэтому регистра у него нет. При этом преобразование в верхний регистр его не меняет, и преобразование в нижний регистр его не меняет, поэтому по 3-му определению он отвечает «да» на оба вопроса: «принадлежишь ли ты к верхнему регистру?» и «принадлежишь ли ты к нижнему регистру?»
Кажется, что из-за этого может возникнуть никому не нужная путаница, однако смысл в том, что определение №3 работает с любой последовательностью символов Unicode, и позволяет упростить алгоритмы преобразования регистра (символы без регистра просто превращаются сами в себя).
Регистр зависит от контекста
Можно подумать, что если таблицы преобразования регистра в Unicode покрывают все символы, то это преобразование заключается просто в поиске нужного места в таблице. К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
Один из примеров, в котором этот подход не работает – греческий язык. Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
Регистр зависит от локали
В разных языках правила преобразования регистра разные. Самый популярный пример: i (U+0069 LATIN SMALL LETTER I) и I (U+0049 LATIN CAPITAL LETTER I) в большинстве локалей преобразовываются друг в друга – в большинстве, но не во всех. В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
Сам Unicode не обрабатывает все возможные правила преобразования регистра для всех локалей. В базе данных Unicode есть только общие правила преобразования всех символов, не зависящие от локали. Также там есть особые правила для некоторых языков и составных форм – литовского языка, тюркских языков, некоторых особенностей греческого. Всего остального там нет. §3.13 стандарта упоминает это и рекомендует при необходимости вводить правила преобразования, зависящие от локали.
Один пример будет знаком англоговорящим – это титульный регистр определённых имён. «o’brian» нужно преобразовывать в «O’Brian» (а не в «O’brian»). Однако при этом «it’s» нужно преобразовывать в «It’s», а не в «It’S». Ещё один пример, который не обрабатывается в Unicode – это голландское буквосочетание «ij», которое при преобразовании в титульный регистр должно переходить в верхний регистр целиком, если стоит в начале слова. Таким образом, большой залив в Нидерландах в титульном регистре будет «IJsselmeer», а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Сравнение без учёта регистра требует приведения к сложенному регистру
Возвращаясь к материалу, представленному в докладе. Сложность работы с регистром в Unicode означает, что регистронезависимое сравнение нельзя проводить при помощи стандартных функций приведения к нижнему или верхнему регистру, имеющихся во многих языках программирования. Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Можно решить, что приведение к сложенному регистру похоже на приведение к нижнему регистру – но это не так. Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
На одном из слайдов моего доклада рекомендации Unicode Technical Report #36 реализуются на Python настолько полно, насколько это возможно. Проводится нормализация NFKC и потом для полученной строки вызывается метод casefold() (доступный только в Python 3+). И даже при этом некоторые крайние случаи выпадают, и это не совсем то, что рекомендуется для сравнения идентификаторов. Сначала плохие новости: Python не выдаёт наружу достаточно свойств Unicode для того, чтобы отфильтровать символы, которых нет в XID_Start или XID_Continue или символы, имеющие свойство Default_Ignorable_Code_Point. Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5.1.
Хорошие новости: большинство этих крайних случаев не связано с какими-либо реальными рисками безопасности, создаваемыми рассматриваемыми символами. И складывание регистра в принципе не определяется как операция, сохраняющая нормализацию (отсюда и отображение NFKC_Casefold, которое повторно нормализуется до NFC после складывания регистра). Как правило, при сравнении вас не волнует, будут ли обе строки нормализованы после предварительной обработки. Вас заботит, не противоречива ли предварительная обработка, и гарантирует ли она, что только строки, которые «должны» отличаться впоследствии, будут отличаться впоследствии. Если вас это беспокоит, вы можете вручную выполнить повторную нормализацию после сложения регистра.
Пока достаточно
Эта статья, как и предыдущий доклад, не является исчерпывающей, и вряд ли можно уложить весь этот материал в единственный пост. Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию. Поэтому в принципе, можно остановиться и тут.
Не будет ли наивной моя надежда на то, что другие люди перестанут писать разоблачения из серии «заблуждения по поводу Х, в которые верят программисты», и начнут уже писать статьи типа «правда, которую должны знать программисты»?