АВЛ-дерево.
АВЛ-дерево – структура данных, изобретенная в 1968 году двумя советскими математиками: Евгением Михайловичем Ландисом и Георгием Максимовичем Адельсон-Вельским. Прежде чем дать конструктивное определение АВЛ-дереву, сделаем это для сбалансированного двоичного дерева поиска.
Сбалансированным называется такое двоичное дерево поиска, в котором высота каждого из поддеревьев, имеющих общий корень, отличается не более чем на некоторую константу k, и при этом выполняются условия характерные для двоичного дерева поиска.
АВЛ-дерево – сбалансированное двоичное дерево поиска с k=1. Для его узлов определен коэффициент сбалансированности (balance factor). Balance factor – это разность высот правого и левого поддеревьев, принимающая одно значение из множества <-1, 0, 1>. Ниже изображен пример АВЛ-дерева, каждому узлу которого поставлен в соответствие его реальный коэффициент сбалансированности.
 Пример АВЛ-дерева
Пример АВЛ-дерева
Положим Bi – коэффициент сбалансированности узла Ti (i – номер узла, отсчитываемый сверху вниз от корневого узла по уровням слева направо). Balance factor узла Ti рассчитывается следующим образом. Пусть функция h() с параметрами Tiи L возвращает высоту левого поддерева L узла Ti, а с Ti и R – правого. Тогда Bi=h(Ti, R)-h(Ti, L). Например, B4=-1, так как h(T4, R)-h(T4, L)=0-1=-1.
Сбалансированное дерево эффективно в обработке, что следует из следующих рассуждений. Максимальное количество шагов, которое может потребоваться для обнаружения нужного узла, равно количеству уровней самого бинарного дерева поиска. А так как поддеревья сбалансированного дерева, «растущие» из произвольного корня, практически симметричны, то и его листья расположены на сравнительно невысоком уровне, т. е. высота дерева сводиться к оптимальному минимуму. Поэтому критерий баланса положительно сказывается на общей производительности. Но в процессе обработки АВЛ-дерева, балансировка может нарушиться, тогда потребуется осуществить операцию балансировки. Помимо нее, над АВЛ-деревом определены операции вставки и удаления элемента. Именно выполнение последних может привести к дисбалансу дерева.
Доказано, что высота АВЛ-дерева, имеющего N узлов, примерно равна log2N. Беря в виду это, а также то, то, что время выполнения операций добавления и удаления напрямую зависит от операции поиска, получим временную сложность трех операций для худшего и среднего случая – O(logN).
Прежде чем рассматривать основные операции над АВЛ-деревом, определим структуру для представления его узлов, а также три специальные функции:
АВЛ-деревья
 Если в одном из моих прошлых постов речь шла о довольно современном подходе к построению сбалансированных деревьев поиска, то этот пост посвящен реализации АВЛ-деревьев — наверное, самого первого вида сбалансированных двоичных деревьев поиска, придуманных еще в 1962 году нашими (тогда советскими) учеными Адельсон-Вельским и Ландисом. В сети можно найти много реализаций АВЛ-деревьев (например, тут), но все, что лично я видел, не внушает особенного оптимизма, особенно, если пытаешься разобраться во всем с нуля. Везде утверждается, что АВЛ-деревья проще красно-черных деревьев, но глядя на прилагаемый к этому код, начинаешь сомневаться в данном утверждении. Собственно, желание объяснить на пальцах, как устроены АВЛ-деревья, и послужило мотивацией к написанию данного поста. Изложение иллюстрируется кодом на С++.
Если в одном из моих прошлых постов речь шла о довольно современном подходе к построению сбалансированных деревьев поиска, то этот пост посвящен реализации АВЛ-деревьев — наверное, самого первого вида сбалансированных двоичных деревьев поиска, придуманных еще в 1962 году нашими (тогда советскими) учеными Адельсон-Вельским и Ландисом. В сети можно найти много реализаций АВЛ-деревьев (например, тут), но все, что лично я видел, не внушает особенного оптимизма, особенно, если пытаешься разобраться во всем с нуля. Везде утверждается, что АВЛ-деревья проще красно-черных деревьев, но глядя на прилагаемый к этому код, начинаешь сомневаться в данном утверждении. Собственно, желание объяснить на пальцах, как устроены АВЛ-деревья, и послужило мотивацией к написанию данного поста. Изложение иллюстрируется кодом на С++.
Понятие АВЛ-дерева
 АВЛ-дерево — это прежде всего двоичное дерево поиска, ключи которого удовлетворяют стандартному свойству: ключ любого узла дерева не меньше любого ключа в левом поддереве данного узла и не больше любого ключа в правом поддереве этого узла. Это значит, что для поиска нужного ключа в АВЛ-дереве можно использовать стандартный алгоритм. Для простоты дальнейшего изложения будем считать, что все ключи в дереве целочисленны и не повторяются.
АВЛ-дерево — это прежде всего двоичное дерево поиска, ключи которого удовлетворяют стандартному свойству: ключ любого узла дерева не меньше любого ключа в левом поддереве данного узла и не больше любого ключа в правом поддереве этого узла. Это значит, что для поиска нужного ключа в АВЛ-дереве можно использовать стандартный алгоритм. Для простоты дальнейшего изложения будем считать, что все ключи в дереве целочисленны и не повторяются.
Особенностью АВЛ-дерева является то, что оно является сбалансированным в следующем смысле: для любого узла дерева высота его правого поддерева отличается от высоты левого поддерева не более чем на единицу. Доказано, что этого свойства достаточно для того, чтобы высота дерева логарифмически зависела от числа его узлов: высота h АВЛ-дерева с n ключами лежит в диапазоне от log2(n + 1) до 1.44 log2(n + 2) − 0.328. А так как основные операции над двоичными деревьями поиска (поиск, вставка и удаление узлов) линейно зависят от его высоты, то получаем гарантированную логарифмическую зависимость времени работы этих алгоритмов от числа ключей, хранимых в дереве. Напомним, что рандомизированные деревья поиска обеспечивают сбалансированность только в вероятностном смысле: вероятность получения сильно несбалансированного дерева при больших n хотя и является пренебрежимо малой, но остается не равной нулю.
Структура узлов
Будем представлять узлы АВЛ-дерева следующей структурой:
Поле key хранит ключ узла, поле height — высоту поддерева с корнем в данном узле, поля left и right — указатели на левое и правое поддеревья. Простой конструктор создает новый узел (высоты 1) с заданным ключом k.
Определим три вспомогательные функции, связанные с высотой. Первая является оберткой для поля height, она может работать и с нулевыми указателями (с пустыми деревьями):
Вторая вычисляет balance factor заданного узла (и работает только с ненулевыми указателями):
Третья функция восстанавливает корректное значение поля height заданного узла (при условии, что значения этого поля в правом и левом дочерних узлах являются корректными):
Заметим, что все три функции являются нерекурсивными, т.е. время их работы есть величина О(1).
Балансировка узлов
Код, реализующий правый поворот, выглядит следующим образом (как обычно, каждая функция, изменяющая дерево, возвращает новый корень полученного дерева):
Левый поворот является симметричной копией правого:
Рассмотрим теперь ситуацию дисбаланса, когда высота правого поддерева узла p на 2 больше высоты левого поддерева (обратный случай является симметричным и реализуется аналогично). Пусть q — правый дочерний узел узла p, а s — левый дочерний узел узла q.

Анализ возможных случаев в рамках данной ситуации показывает, что для исправления расбалансировки в узле p достаточно выполнить либо простой поворот влево вокруг p, либо так называемый большой поворот влево вокруг того же p. Простой поворот выполняется при условии, что высота левого поддерева узла q больше высоты его правого поддерева: h(s)≤h(D).
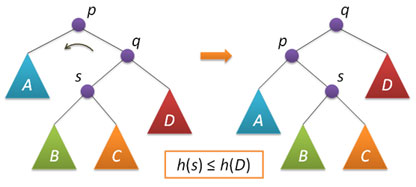
Большой поворот применяется при условии h(s)>h(D) и сводится в данном случае к двум простым — сначала правый поворот вокруг q и затем левый вокруг p.

Код, выполняющий балансировку, сводится к проверке условий и выполнению поворотов:
Описанные функции поворотов и балансировки также не содержат ни циклов, ни рекурсии, а значит выполняются за постоянное время, не зависящее от размера АВЛ-дерева.
Вставка ключей
Вставка нового ключа в АВЛ-дерево выполняется, по большому счету, так же, как это делается в простых деревьях поиска: спускаемся вниз по дереву, выбирая правое или левое направление движения в зависимости от результата сравнения ключа в текущем узле и вставляемого ключа. Единственное отличие заключается в том, что при возвращении из рекурсии (т.е. после того, как ключ вставлен либо в правое, либо в левое поддерево, и это дерево сбалансировано) выполняется балансировка текущего узла. Строго доказывается, что возникающий при такой вставке дисбаланс в любом узле по пути движения не превышает двух, а значит применение вышеописанной функции балансировки является корректным.
Чтобы проверить соответствие реализованного алгоритма вставки теоретическим оценкам для высоты АВЛ-деревьев, был проведен несложный вычислительный эксперимент. Генерировался массив из случайно расположенных чисел от 1 до 10000, далее эти числа последовательно вставлялись в изначально пустое АВЛ-дерево и измерялась высота дерева после каждой вставки. Полученные результаты были усреднены по 1000 расчетам. На следующем графике показана зависимость от n средней высоты (красная линия); минимальной высоты (зеленая линия); максимальной высоты (синяя линия). Кроме того, показаны верхняя и нижняя теоретические оценки.
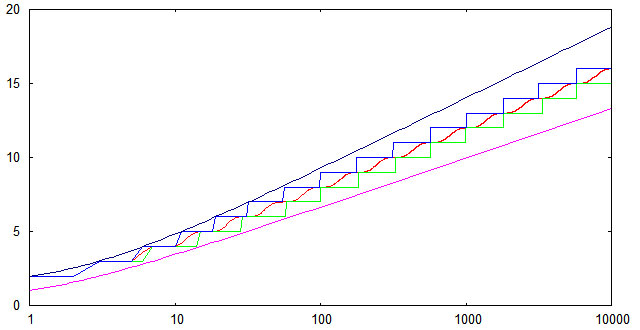
Видно, что для случайных последовательностей ключей экспериментально найденные высоты попадают в теоретические границы даже с небольшим запасом. Нижняя граница достижима (по крайней мере в некоторых точках), если исходная последовательность ключей является упорядоченной по возрастанию.
Удаление ключей
С удалением узлов из АВЛ-дерева, к сожалению, все не так шоколадно, как с рандомизированными деревьями поиска. Способа, основанного на слиянии (join) двух деревьев, ни найти, ни придумать не удалось. 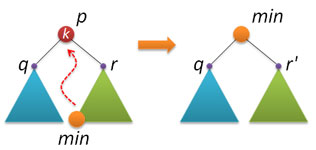 Поэтому за основу был взят вариант, описываемый практически везде (и который обычно применяется и при удалении узлов из стандартного двоичного дерева поиска). Идея следующая: находим узел p с заданным ключом k (если не находим, то делать ничего не надо), в правом поддереве находим узел min с наименьшим ключом и заменяем удаляемый узел p на найденный узел min.
Поэтому за основу был взят вариант, описываемый практически везде (и который обычно применяется и при удалении узлов из стандартного двоичного дерева поиска). Идея следующая: находим узел p с заданным ключом k (если не находим, то делать ничего не надо), в правом поддереве находим узел min с наименьшим ключом и заменяем удаляемый узел p на найденный узел min.
При реализации возникает несколько нюансов. Прежде всего, если у найденный узел p не имеет правого поддерева, то по свойству АВЛ-дерева слева у этого узла может быть только один единственный дочерний узел (дерево высоты 1), либо узел p вообще лист. В обоих этих случаях надо просто удалить узел p и вернуть в качестве результата указатель на левый дочерний узел узла p.
Пусть теперь правое поддерево у p есть. Находим минимальный ключ в этом поддереве. По свойству двоичного дерева поиска этот ключ находится в конце левой ветки, начиная от корня дерева. Применяем рекурсивную функцию:
Еще одна служебная функция у нас будет заниматься удалением минимального элемента из заданного дерева. Опять же, по свойству АВЛ-дерева у минимального элемента справа либо подвешен единственный узел, либо там пусто. В обоих случаях надо просто вернуть указатель на правый узел и по пути назад (при возвращении из рекурсии) выполнить балансировку. Сам минимальный узел не удаляется, т.к. он нам еще пригодится.
Теперь все готово для реализации удаления ключа из АВЛ-дерева. Сначала находим нужный узел, выполняя те же действия, что и при вставке ключа:
Как только ключ k найден, переходим к плану Б: запоминаем корни q и r левого и правого поддеревьев узла p; удаляем узел p; если правое поддерево пустое, то возвращаем указатель на левое поддерево; если правое поддерево не пустое, то находим там минимальный элемент min, потом его извлекаем оттуда, слева к min подвешиваем q, справа — то, что получилось из r, возвращаем min после его балансировки.
При выходе из рекурсии не забываем выполнить балансировку:
Вот собственно и все! Поиск минимального узла и его извлечение, в принципе, можно реализовать в одной функции, при этом придется решать (не очень сложную) проблему с возвращением из функции пары указателей. Зато можно сэкономить на одном проходе по правому поддереву.
Очевидно, что операции вставки и удаления (а также более простая операция поиска) выполняются за время пропорциональное высоте дерева, т.к. в процессе выполнения этих операций производится спуск из корня к заданному узлу, и на каждом уровне выполняется некоторое фиксированное число действий. А в силу того, что АВЛ-дерево является сбалансированным, его высота зависит логарифмически от числа узлов. Таким образом, время выполнения всех трех базовых операций гарантированно логарифмически зависит от числа узлов дерева.
Сбалансированные двоичные деревья поиска: реализация на Julia
Иллюстрация из работы Г.М. Адельсон-Вельского и Е.М. Ландиса 1962 года
Деревья поиска — это структуры данных для упорядоченного хранения и простого поиска элементов. Широко применяются двоичные деревья поиска, в которых у каждого узла есть только два потомка. В этой статье рассмотрим два метода организации двоичных деревьев поиска: алгоритм Адельсон-Вельского и Ландиса (АВЛ-деревья) и ослабленные АВЛ-деревья (WAVL-деревья).
Начнём с определений. Двоичное дерево состоит из узлов, каждый узел хранит запись в виде пар ключ-значение (либо, в простом случае, только значений) и имеет не более двух потомков. Узлы-потомки различаются на правый и левый, причём выполняется условие на упорядоченность ключей: ключ левого потомка не больше, а правого — не меньше, чем ключ родительского узла. Дополнительно в узлах может храниться (и обычно хранится) служебная информация — например, ссылка на родительский узел или другие данные. Специальными случаями являются корневой узел, с которого происходит вход в дерево, и пустой узел, который не хранит никакой информации. Узлы, у которых оба потомка пустые, называются листьями дерева. Узел со всеми потомками образует поддерево. Таким образом, каждый узел либо является корнем какого-то поддерева, либо листом.
В этом случае возникает вопрос, каким образом представить пустое дерево. Воспользуемся для этого подходом из книги «Алгоритмы: построение и анализ» и вставим в качестве точки входа в дерево не корень, а фиктивный узел, который будет своим собственным родителем. Для создания такого узла нужно добавить в описание структуры BSTNode конструкторы:
В этом случае структуру BST можно сделать неизменяемой, т.к. ссылку на точку входа менять уже не потребуется. Далее будем считать, что корневой узел дерева является сразу и правым, и левым потомком входного узла.
Главная операция, для которой нужны деревья поиска — это, естественно, поиск элементов. Поскольку ключ левого потомка не больше, а правого — не меньше родительского ключа, процедура поиска элемента пишется очень просто: начиная с корня дерева, сравниваем входной ключ с ключом текущего узла; если ключи совпали — возвращаем значение, в противном случае переходим к левому или правому поддереву, в зависимости от порядка ключей. Если при этом дошли до пустого узла — ключа в дереве нет, бросаем исключение.
Естественно, алгоритм добавления элемента в дерево поиска нужно строить таким образом, чтобы условие на порядок ключей выполнялся. Напишем наивную реализацию вставки элемента по ключу:
К сожалению, наивное построение дерева даст нужную структуру только на случайных входных данных, а в реальности они часто довольно сильно структурированы. В наихудшем случае, если поступающие ключи строго упорядочены (хоть по возрастанию, хоть по убыванию), наивное построение дерева будет отправлять новые элементы всё время в одну сторону, собирая, по сути, линейный список. Как нетрудно догадаться, что вставка элементов, что поиск будут при такой структуре происходить за время O(N), что сводит на нет все усилия по построению сложной структуры данных.
Вывод: дерево поиска при построении нужно балансировать, т.е. выравнивать высоту правого и левого поддерева у каждого узла. К балансировке есть несколько подходов. Простейший — задать некоторое число операций вставки или удаления, после которого будет производиться перебалансировка дерева. В таком случае дерево будет перед балансировкой будет в довольно «запущенном» состоянии, из-за чего балансировка будет занимать время порядка O(N) в худшем случае, зато последующие операции до некоторого порога вставок/удалений будут выполняться за логарифмическое время. Другой же вариант — строить алгоритмы вставки и удаления сразу так, чтобы дерево постоянно оставалось сбалансированным, что даёт для любой операции гарантированную временную сложность O(log2N).
В связи с тем, что есть алгоритмы, в которых дереву позволяют «разбалтываться», но после этого довольно долго операции можно проводить за логарифмическое время, прежде чем придётся долго приводить дерево обратно в сбалансированное состояние, различают гарантированное и амортизированное время вставки/удаления элемента. Для некоторых реализаций операций с двоичными деревьями поиска сложность вставки и удаления O(log2N) является гарантированной, для некоторых — амортизированной, с ухудшением до O(N).
Алгоритм Адельсон-Вельского и Ландиса (АВЛ)
Первая реализация самобалансирующегося двоичного дерева поиска была предложена в 1962 году Адельсоном-Вельским и Ландисом. В современной литературе по начальным буквам фамилий эта структура называется АВЛ-деревья. Структура описывается следующими свойствами:
Из этих свойств следует, что высота всего дерева составляет O(log2N), где N — число хранимых в дереве записей, а значит, поиск записи происходит за логарифмическое время. Чтобы условие АВЛ-сбалансированности сохранялось после каждой вставки, каждая вставка сопровождается операцией балансировки. Для эффективного осуществления этой операции в каждом узле нужно хранить служебную информацию. Для простоты, пусть там просто хранится высота узла.
Вставка записи
Далее, идём вверх по дереву и ищем нарушения условий 2 и 3. Далее рассмотрим варианты, которые могут появиться (на рисунках зелёным обозначен узел, поменявший высоту, обрабатываемый узел — его родитель).
Случай 0
После вставки высота узла стала такой же, как у сестринского, и на 1 меньше (старой) высоты родительского узла.
Самый лучший случай, ничего дальше трогать не надо. Выше тоже уже можно не смотреть, т.к. там ничего не поменяется.
Случай 1
До вставки высота узла была равна высоте сестринского узла. Вставка поднимает корень поддерева, и высота узла сравнивается с высотой родителя.
В этом случае достаточно «поднять» родительский узел, увеличив его высоту на 1. При этом нужно продолжить двигаться к корню дерева, поскольку изменение высоты родительского узла могло привести к нарушению условия 2 на уровень выше.
Случай 2
После вставки разница высот с сестринским поддеревом стала 2, причём «вытолкнуло» вверх левое поддерево:
Проблема лечится операцией, называемой «простой поворот», преобразующей дерево следующим образом:
На простой поворот требуется 6 изменений указателей.
Обратите внимание, что в проекции на горизонтальную ось порядок вершин n, p и деревьев T1 — T3 до и после поворота остаётся одним и тем же. Это — выполнение условия упорядоченности. Как видно, после выполнения поворота выше по дереву балансировка уже не требуется.
Случай 3
После вставки разница высот с сестринским поддеревом стала 2, причём «вытолкнуло» вверх правое поддерево:
В этом случае одиночный простой поворот уже не поможет, но можно сделать простой поворот влево вокруг правого потомка, что приведёт ситуацию к случаю 2, который уже лечится простым поворотом вправо.
Для уменьшения количества «перевешиваний» узлов можно два поворота скомпоновать в одну операцию, называемую большим, или двойным поворотом. Тогда вместо 12 изменений указателей нужно будет только 10. В итоге двойного поворота дерево приобретает следующий вид:
Как видно, после двойного поворота дальнейшей балансировки выше по дереву также не требуется.
Функция fix_insertion!() проверяет разницу высот двух дочерних узлов, начиная с родительского узла от вставленного. Если она равна 1 — мы находимся в случае 1, нужно поднять высоту узла и пройти выше. Если она ноль — дерево сбалансировано. Если она равна 2 — это случай 2 или 3, нужно применить соответствующий поворот, и дерево приходит к сбалансированному состоянию.
Удаление записи
Удаление несколько сложнее вставки.
Для начала рассмотрим обычное удаление записи из двоичного дерева поиска.
Но после этого может нарушиться баланс дерева, поэтому от родителя удалённого узла нужно пройтись вверх, восстанавливая его. Заметим, что в самом начале гарантированно один из потомков рассматриваемого родителя уменьшил высоту на 1. С учётом этого нужно рассмотреть варианты (красным показаны узлы, поменявшие высоту, обрабатываемый узел — родительский от красного):
Случай 1
Нулевой дисбаланс. Значит, до удаления он был 1 по модулю, и теперь дочерние узлы на 2 ниже материнского.
Нужно опустить родительский узел на 1 и продолжить движение вверх.
Случай 2
Дисбаланс 1 по модулю.
АВЛ-условие выполнено, можно остановиться.
Случай 3
Дисбаланс 2 по модулю, сестринский узел к опустившемуся имеет ненулевой дисбаланс.
Восстанавливаем баланс простым (если T1 ниже, чем T2) или двойным (в обратном случае) поворотом, как делали при вставке. Высота поддерева при этом уменьшается, т.е. может возникнуть нарушение выше по дереву.
Случай 4
Дисбаланс 2 по модулю, сестринский узел имеет нулевой дисбаланс.
Простой поворот восстанавливает условие балансировки, высота поддерева при этом не меняется — останавливаем движение наверх.
Взлёт и падение АВЛ-деревьев
Из-за этой не очень хорошей асимптотики АВЛ-деревья уступили место появившимся в 1970-х красно-чёрным деревьям, у которых более слабое условие балансировки — путь от корня до самого дальнего листа не более чем вдвое превышает путь от корня до самого ближнего листа. Из-за этого высота красно-чёрных деревьев составляет в худшем случае 2log2N против 1,44log2N у АВЛ-деревьев, зато удаление записи требует не более трёх простых поворотов. Таким образом, поиск и вставка за счёт более высокой высоты дерева потенциально проигрывают в производительности, зато есть потенциальный выигрыш, если вставки часто перемежаются удалениями.
АВЛ наносят ответный удар
Получается, что «идеальный» алгоритм построения двоичных деревьев поиска должен гарантировать небольшую высоту (на уровне классического АВЛ-дерева) и константное число поворотов как при добавлении, так и при удалении записи. Такого пока не придумано, но в 2015 году была опубликована работа, где предложена структура, улучшающая свойства как АВЛ, так и красно-чёрных деревьев. Идея лежит ближе к АВЛ деревьям, но условие баланса ослаблено, чтобы позволить более эффективное удаление записей. Свойства структуры, названной «слабым АВЛ-деревом» (W(eak)AVL-деревом) формулируются таким образом:
Оказывается, что такая структура включает в себя свойства и классических АВЛ-деревьев, и красно-чёрных деревьев. В частности, если ввести условие, что оба дочерних узла не могут отличаться от родительского по рангу на 2, то получится обычное АВЛ дерево, а ранг будет точно совпадать с высотой поддерева.
Код поворотов немного меняется, чтобы не писать разные функции для поворота при вставке и удалении. При вставке, учитывая конфигурации, которые там могут возникать, он работает так же, как в обычном АВЛ-дереве, для удаления чуть-чуть иначе.
Удаление записи
Поиск узла для удаления, поиск следующего и замена — полностью идентичны обычным АВЛ-деревьям. Для балансировки при обратном проходе рассматриваются следующие случаи.
Случай 0
Ни одно из условий баланса не нарушено, т.е.:
Случай 1
Имеем лист с рангом 2 (дисбаланс 0, поддеревья на 2 ниже и пустые).
Присваиваем узлу ранг 1 и переходим выше.
Случай 2
Дисбаланс 1, разница с максимальным поддеревом 2.
Уменьшаем у узла ранг на 1, переходим выше.
Случай 3
Дисбаланс 2 (разница с максимальным поддеревом автоматически 1, т.к. иначе слабое АВЛ условие было бы нарушено ещё до удаления), у более высокого потомка оба поддерева рангом на 2 ниже его.
Спускаем на ранг ниже и сам узел, и более высокого потомка. Переходим выше.
Случай 4
Лечится простым поворотом.
Обратите внимание, что за счёт ослабленного АВЛ условия поворот можно сделать так, что всё поддерево не меняет высоту, т.е. выше по дереву балансировка не требуется.
Единственная тонкость — если деревья T1 и T2 оба пустые, то p становится листом с рангом 2, что лечится присваиванием p в этом случае ранга 1.
Случай 5
Лечится двойным поворотом.
Аналогично, высота поддерева не меняется, и балансировку можно на этом заканчивать.
Проверим в сравнении со встроенными хэш-таблицами.
Итак, скорость поиска по ключу вышла примерно такая же, как во встроенных словарях. И, ожидаемо, в классическом АВЛ-дереве скорость поиска чуть выше, чем в САВЛ-дереве, за счёт лучшей сбалансированности.
Применение деревьев поиска
И основной вопрос — зачем это нужно?
Простейший ответ — деревья поиска нужны, чтобы искать информацию. Но, на самом деле, не только.
На основе двоичных деревьев поиска можно реализовать различные абстрактные структуры данных.
Упорядоченное множество
Задача упорядоченного множества — хранить элементы так, чтобы к ним можно было доступаться в порядке возрастания или убывания. Также можно ввести операцию поиска n-го по величине элемента. Естественно, структуру данных рассматриваем как динамическую, т.е. кроме перечисления, мы хотим добавлять или удалять оттуда элементы.
| Операция | АВЛ дерево | Сортированный массив |
|---|---|---|
| Перечислить все элементы | O(N) | O(N) |
| Вставка | O(logN) | O(N) |
| Удаление | O(logN) | O(N) |
| n-й элемент | O(logN)* | O(1) |
* если в узлах хранить информацию о размере поддерева
Ассоциативный массив
Ассоциативный массив — абстрактная структура данных, для которой основными операциями являются «найти запись по ключу», «проверить наличие ключа в массиве», «добавить пару ключ-значение», «удалить запись». Во многих языках программирования, где структура включена в стандартную библиотеку, реализация сделана с помощью двоичных деревьев или хэш-таблиц. Языки семейства Лисп поддерживают ассоциативные списки. В конце концов, записи можно даже просто хранить в массиве в отсортированном порядке.
| Операция | АВЛ дерево | хэш-таблица | Список | Сортированный массив |
|---|---|---|---|---|
| Поиск | O(logN) | O(1)* | O(N) | O(logN) |
| Вставка | O(logN) | O(1)* | O(1) | O(N) |
| Удаление | O(logN) | O(1)* | O(N)** | O(N) |
| Поиск ближайшего ключа | O(logN) | O(N) | O(N) | O(logN) |
* амортизированная стоимость операции
** само удаление делается за O(1), но ключ ещё нужно найти.
Очередь с приоритетами
Это такая структура данных, где хранятся записи в виде пар «приоритет — данные». Извлекаются записи не в порядке поступления, а в порядке приоритета. Основные операции — посмотреть элемент с максимальным (или минимальным) приоритетом, удалить из очереди запись со старшим приоритетом, добавить запись, изменить приоритет записи. Часто такие очереди реализуются при помощи двоичной кучи.
| Операция | АВЛ дерево | Двоичная куча | Список | Сортированный список/массив |
|---|---|---|---|---|
| Посмотреть максимум | O(1)* | O(1) | O(N) | O(1) |
| Удалить максимум | O(logN) | O(logN) | O(N) | O(1)** |
| Добавить запись | O(logN) | O(logN) | O(1) | O(N) |
| Изменить приоритет | O(logN) | O(logN) | O(N) | O(N) |
* если добавить в структуру указатель на максимум
** если считать, что максимум находится в конце массива
Вывод
(самобалансирующиеся) Двоичные деревья поиска — неплохая структура данных для реализации ассоциативных массивов, очередей с приоритетами, и, в первую очередь, множеств, где важно упорядочение элементов. Главная сильная черта деревьев поиска — гибкость в плане области применения, т.к. нельзя сказать, что для любой задачи деревья поиска обеспечат лучшую производительность, чем специализированные структуры.