Хранение данных. Или что такое NAS, SAN и прочие умные сокращения простыми словами
TL;DR: Вводная статья с описанием разных вариантов хранения данных. Будут рассмотрены принципы, описаны преимущества и недостатки, а также предпочтительные варианты использования.

Зачем это все?
Хранение данных — одно из важнейших направлений развития компьютеров, возникшее после появления энергонезависимых запоминающих устройств. Системы хранения данных разных масштабов применяются повсеместно: в банках, магазинах, предприятиях. По мере роста требований к хранимым данным растет сложность хранилищ данных.
Надежно хранить данные в больших объемах, а также выдерживать отказы физических носителей — весьма интересная и сложная инженерная задача.
Хранение данных
Под хранением обычно понимают запись данных на некоторые накопители данных, с целью их (данных) дальнейшего использования. Опустим исторические варианты организации хранения, рассмотрим подробнее классификацию систем хранения по разным критериям. Я выбрал следующие критерии для классификации: по способу подключения, по типу используемых носителей, по форме хранения данных, по реализации.
По способу подключения есть следующие варианты:

подключение дисков в сервере

дисковая полка, подключаемая по FC
По типу используемых накопителей возможно выделить:
Если рассматривать форму хранения данных, то явно выделяются следующие:
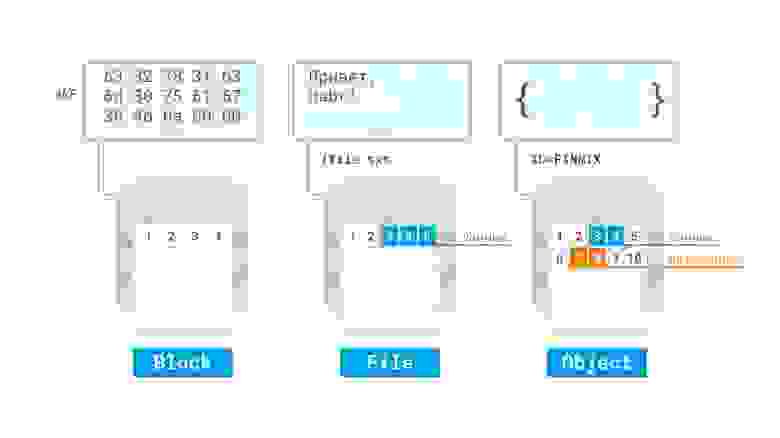
По реализации достаточно сложно провести четкие границы, однако можно отметить:

RAID контроллер от компании Fujitsu
пример организации LVM с шифрованием и избыточностью в виртуальной машине Linux в облаке Azure
Давайте рассмотрим более детально некоторые технологии, их достоинства и недостатки.
Direct Attached Storage — это исторически первый вариант подключения носителей, применяемый до сих пор. Накопитель, с точки зрения компьютера, в котором он установлен, используется монопольно, обращение с накопителем происходит поблочно, обеспечивая максимальную скорость обмена данными с накопителем с минимальными задержками. Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
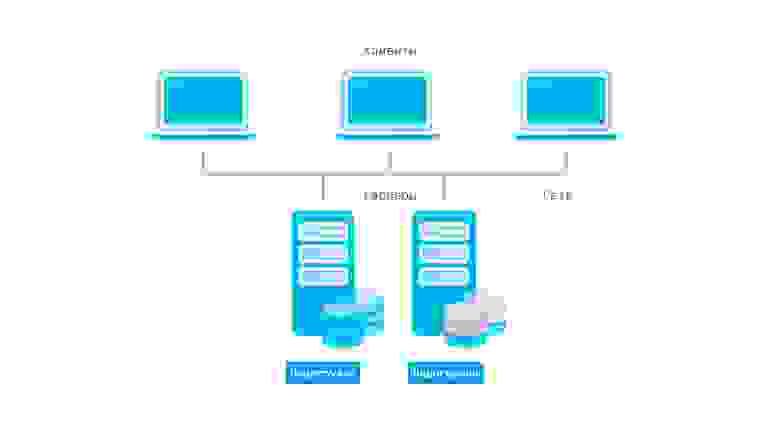
Конфигурации систем с единственным накопителем применяются чаще всего для нетребовательных нагрузок, обычно для домашнего применения. Для профессиональных целей, а также промышленного применения чаще всего используется несколько накопителей, объединенных в RAID-массив программно, либо с помощью аппаратной карты RAID для достижения отказоустойчивости и\или более высокой скорости работы, чем единичный накопитель. Также есть возможность организации кэширования наиболее часто используемых данных на более быстром, но менее емком твердотельном накопителе для достижения и большой емкости и большой скорости работы дисковой подсистемы компьютера.
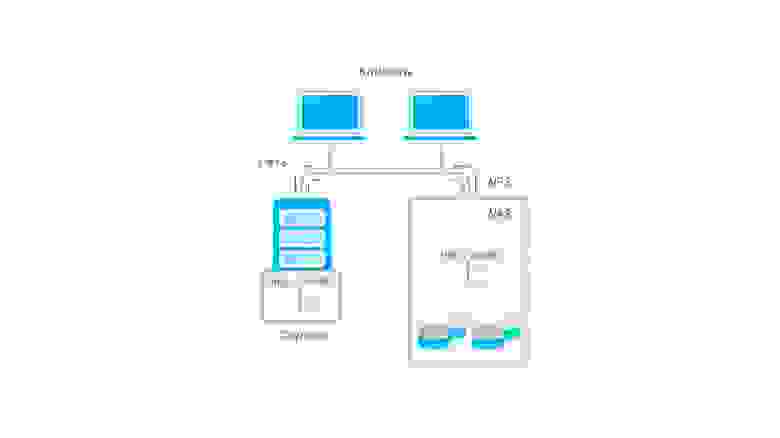
Storage area network, она же сеть хранения данных, является технологией организации системы хранения данных с использованием выделенной сети, позволяя таким образом подключать диски к серверам с использованием специализированного оборудования. Так решается вопрос с утилизацией дискового пространства серверами, а также устраняются точки отказа, неизбежно присутствующие в системах хранения данных на основе DAS. Сеть хранения данных чаще всего использует технологию Fibre Channel, однако явной привязки к технологии передачи данных — нет. Накопители используются в блочном режиме, для общения с накопителями используются протоколы SCSI и NVMe, инкапсулируемые в кадры FC, либо в стандартные пакеты TCP, например в случае использования SAN на основе iSCSI.

Давайте разберем более детально устройство SAN, для этого логически разделим ее на две важных части, сервера с HBA и дисковые полки, как оконечные устройства, а также коммутаторы (в больших системах — маршрутизаторы) и кабели, как средства построения сети. HBA — специализированный контроллер, размещаемый в сервере, подключаемом к SAN. Через этот контроллер сервер будет «видеть» диски, размещаемые в дисковых полках. Сервера и дисковые полки не обязательно должны размещаться рядом, хотя для достижения высокой производительности и малых задержек это рекомендуется. Сервера и полки подключаются к коммутатору, который организует общую среду передачи данных. Коммутаторы могут также соединяться с собой с помощью межкоммутаторных соединений, совокупность всех коммутаторов и их соединений называется фабрикой. Есть разные варианты реализации фабрики, я не буду тут останавливаться подробно. Для отказоустойчивости рекомендуется подключать минимум две фабрики к каждому HBA в сервере (иногда ставят несколько HBA) и к каждой дисковой полке, чтобы коммутаторы не стали точкой отказа SAN.
Недостатками такой системы являются большая стоимость и сложность, поскольку для обеспечения отказоустойчивости требуется обеспечить несколько путей доступа (multipath) серверов к дисковым полкам, а значит, как минимум, задублировать фабрики. Также в силу физических ограничений (скорость света в общем и емкость передачи данных в информационной матрице коммутаторов в частности) хоть и существует возможность неограниченного подключения устройств между собой, на практике чаще всего есть ограничения по числу соединений (в том числе и между коммутаторами), числу дисковых полок и тому подобное.
Network attached storage, или сетевое файловое хранилище, представляет дисковые ресурсы в виде файлов (или объектов) с использованием сетевых протоколов, например NFS, SMB и прочих. Принципиально базируется на DAS, но ключевым отличием является предоставление общего файлового доступа. Так как работа ведется по сети — сама система хранения может быть сколько угодно далеко от потребителей (в разумных пределах разумеется), но это же является и недостатком в случае организации на предприятиях или в датацентрах, поскольку для работы утилизируется полоса пропускания основной сети — что, однако, может быть нивелировано с использованием выделенных сетевых карт для доступа к NAS. Также по сравнению с SAN упрощается работа клиентов, поскольку сервер NAS берет на себя все вопросы по общему доступу и т.п.
Unified storage
Универсальные системы, позволяющие совмещать в себе как функции NAS так и SAN. Чаще всего по реализации это SAN, в которой есть возможность активировать файловый доступ к дисковому пространству. Для этого устанавливаются дополнительные сетевые карты (или используются уже существующие, если SAN построена на их основе), после чего создается файловая система на некотором блочном устройстве — и уже она раздается по сети клиентам через некоторый файловый протокол, например NFS.
Software-defined storage — программно определяемое хранилище данных, основанное на DAS, при котором дисковые подсистемы нескольких серверов логически объединяются между собой в кластер, который дает своим клиентам доступ к общему дисковому пространству.
Наиболее яркими представителями являются GlusterFS и Ceph, но также подобные вещи можно сделать и традиционными средствами (например на основе LVM2, программной реализации iSCSI и NFS).
N.B. редактора: У вас есть возможность изучить технологию сетевого хранилища Ceph, чтобы использовать в своих проектах для повышения отказоустойчивости, на нашем практическим курсе по Ceph. В начале курса вы получите системные знания по базовым понятиям и терминам, а по окончании научитесь полноценно устанавливать, настраивать и управлять Ceph. Детали и полная программа курса здесь.
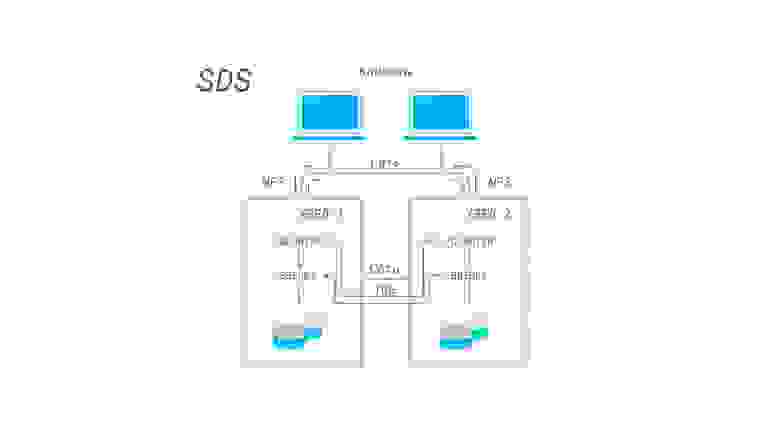
Пример SDS на основе GlusterFS
Из преимуществ SDS — можно построить отказоустойчивую производительную реплицируемую систему хранения данных с использованием обычного, возможно даже устаревшего оборудования. Если убрать зависимость от основной сети, то есть добавить выделенные сетевые карты для работы SDS, то получается решение с преимуществами больших SAN\NAS, но без присущих им недостатков. Я считаю, что за подобными системами — будущее, особенно с учетом того, что быстрая сетевая инфраструктура более универсальная (ее можно использовать и для других целей), а также дешевеет гораздо быстрее, чем специализированное оборудование для построения SAN. Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
Гиперконвергентные системы
Подавляющее большинство систем хранения данных используется для организации дисков виртуальных машин, при использовании SAN неизбежно происходит удорожание инфраструктуры. Но если объединить дисковые системы серверов с помощью SDS, а процессорные ресурсы и оперативную память с помощью гипервизоров отдавать виртуальным машинам, использующим дисковые ресурсы этой SDS — получится неплохо сэкономить. Такой подход с тесной интеграцией хранилища совместно с другими ресурсами называется гиперконвергентностью. Ключевой особенностью тут является способность почти бесконечного роста при нехватке ресурсов, поскольку если не хватает ресурсов, достаточно добавить еще один сервер с дисками к общей системе, чтобы нарастить ее. На практике обычно есть ограничения, но в целом наращивать получается гораздо проще, чем чистую SAN. Недостатком является обычно достаточно высокая стоимость подобных решений, но в целом совокупная стоимость владения обычно снижается.
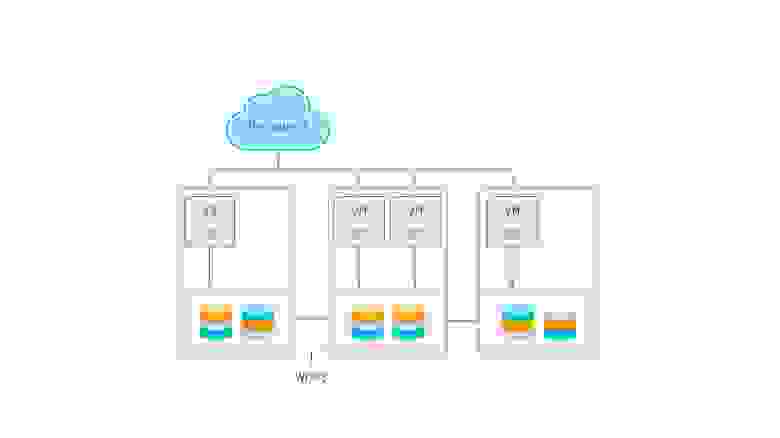
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless). Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные. Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.

Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
Заключение
Надеюсь, статья была полезной не только новичкам. Предлагаю обсудить в комментариях дополнительные возможности систем хранения данных, написать о своем опыте построения систем хранения данных.
Системы хранения данных
Содержание
Предисловие [ править ]
Материал, по близким, но выходящим за рамки данного учебника, темам лучше добавлять в учебник «Информационная Инфраструктура».
На странице обсуждения приведена задумка данной книги. Там же происходит ее обсуждение.
Введение [ править ]
История вопроса [ править ]
Протоколы [ править ]
SCSI [ править ]
iSCSI [ править ]
Технология iSCSI (ныне входит в употребление термин IP-SAN) — метод для организации SAN-сети через обычную сетевую инфраструктуру Ethernet. Она прошла ратификацию в IETF в конце 2003 года (RFC3720) и на сегодняшний день является широкораспространенной и стандартной.
iSCSI является функциональным эквивалентом известного протокола FibrеChannel, также как FC, технология iSCSI позволяет организовывать сеть хранения данных, подключать к серверам или рабочим станциям диски и иные устройства хранения (например, ленточные устройства для бэкапа) с тем, чтобы использовать их так, как будто они подключены непосредственно к этим компьютерам.
Технически это осуществляется путем инкапсулирования («заворачивания») команд и блоков данных обычного SCSI в IP-пакеты. Это достаточно обычная и традиционная для IP технология, используемая не только в iSCSI. «Обернутые» в IP пакеты SCSI («SCSI-over-IP») могут пересылаться по обычной сети Ethernet или даже Интернету. Попадая к получателю, они извлекаются из «обертки» IP и в дальнейшем, с точки зрения конечного пользователя, это те же самые SCSI-пакеты, словно они прошли не через Ethernet, а через обыкновенный SCSI-кабель.
Строго говоря то, что мы привыкли называть FibreChannel (FC), есть на самом деле «SCSI-over-FC», то есть точно таким же образом пакеты FC переносят блоки и команды SCSI, и разница с iSCSI тут на «транспортном уровне». А существует, например, «Video-over-FC», ограниченно применяется в высокопроизводительных системах видеообработки, например в «боевых» авиационных симуляторах.
Преимуществом же iSCSI является то, что он работает всюду, где пройдет обычный IP, что на практике означает «вообще всюду». Хоть по модему, хоть через всю планету. На практике же обычно используется уже достаточно широкораспространенный Gigabit Ethernet, обеспечивающий «скорость провода» около 1GBit в секунду (около 100 мегабайт в секунду), не считая возможности объединить провода в «агрегированные каналы», пропорционально увеличивающие эту скорость.
Широкая доступность Ethernet-инфраструктуры означает в том числе и ее дешевизну в практической реализации. В наше время, когда стоимость порта Gigabit Ethernet снижается на 30 % ежемесячно, и дешевые GigE switch доступны уже даже для домашнего использования, это является довольно значимым и существенным аспектом.
Поскольку носителем iSCSI является «вездеходный» IP, то автоматически решается проблема, связанная с передачей SAN-сети на большие расстояния — то, для чего в случае FC создаются разнообразные конвертеры, бриджи и DWDM-директоры. С iSCSI нет проблем осуществить резервное копирование или репликацию через SAN на устройство, расположенное в удаленном датацентре. При этом не нужны никакой бридж для преобразования SAN-сети в вид пригодный для передачи по IP-сети «общего пользования» или наличие оптической магистрали для передачи траффика FC между сегментами SAN.
Когда говорят о «бесплатности», то имеют ввиду софтверный initiator, тот самый модуль, который позволяет использовать функциональность iSCSI и осуществляет рассмотренную выше инкапсуляцию и декапсуляцию SCSI в IP. Однако, как любое софтверное решение, это потребляет какое-то количество процессорной мощности. В реальной жизни, на доступных сегодня процессорах, эта величина стремится к единицам процентов. Но, тем не менее, в ряде случаев она может играть свою роль.
Конечно, существуют и «аппаратные» реализации в виде iSCSI HBA (пример: QLogic QLA4050), снимающие эти проблемы, однако они уже отнюдь не бесплатные, и, хоть и стоят дешевле большинства FC HBA, все же существенно увеличивают бюджет проекта.
Однако, в реальной жизни, в практических задачах применимость и безусловная нужность iSCSI HBA вовсе не настолько бесспорна. Если идти не от абстрактной «производительности системы хранения», а от производительности информационной системы в целом, то беспокоить скорость передачи данных между дисковой системой и сервером должна, пожалуй, в последнюю очередь. Обычно прикладной задаче, например ERP или CRM-системе, всегда есть где потормозить и не упираясь в канал передачи данных между дисками и процессором.
Скорость iSCSI не использующего «агрегирование каналов» (объеднение вместе нескольких портов для увеличения пропускной способности) в настоящий момент равна 1Gb/s. Несмотря на то, что уже появились сетевые устройства стандарта 10G Ethernet со скоростью до 10Gb/s, цена на них пока все еще высока, что не позволяет говорить о них как о среде для iSCSI. Скорость FC для наиболее распространенных FC-устройств равна 2 и 4Gb/s, что формально вдвое-вчетверо выше. Однако в условиях «реальной жизни» наличие на устройстве порта 4Gb/s не делает скорость работы устройства вчетверо выше, чем с портом 1Gb/s.
Что необходимо для использования iSCSI:
Для построения простейшей SAN необходимо наличие дискового массива с поддержкой интерфейса iSCSI (например любой NetApp FAS), отдельного сегмента сети передачи данных (несмотря на то, что траффик iSCSI может идти и по обычной «офисной» LAN, более грамотно выделить его в отдельную сеть), свободных Ethernet портов в серверах или специального iSCSI адаптера, а так же программный компонент «Initiator» под ОС серверов.
Где применять iSCSI:
Где не применять iSCSI:
Fibre Channel [ править ]
Технология хранения Redundant array of independent disks (RAID) [ править ]
RAID — аббревиатура, расшифровываемая как Redundant Array of Independent Disks — «отказоустойчивый массив из независимых дисков» (раньше иногда вместо Independent использовалось слово Inexpensive). Концепция структуры, состоящей из нескольких дисков, объединенных в группу, обеспечивающую отказоустойчивость родилась в 1987 году в основополагающей работе Паттерсона, Гибсона и Катца.
типы RAID [ править ]
RAID-0 [ править ]
Если мы считаем, что RAID это «отказоустойчивость»(Redundant…), то RAID-0 это «нулевая отказоустойчивость», отсутствие ее. Структура RAID-0 это «массив дисков с чередованием». Блоки данных поочередно записываются на все входящие в массив диски, по порядку. Это повышает быстродействие, в идеале во столько раз, сколько дисков входит в массив, так как запись распараллеливается между несколькими устройствами. Однако во столько же раз снижается надежность, поскольку данные будут потеряны при выходе из строя любого из входящих в массив дисков.
RAID-1 [ править ]
Это так называемое «зеркало». Операции записи производятся на два диска параллельно. Надежность такого массива выше, чем у одиночного диска, однако быстродействие повышается незначительно (в современных «умных» контроллерах обычно работает распараллеливание чтения между зеркальными дисками, что дает, в теории двукратное повышение показателей), или не повышается вовсе.
RAID-2 [ править ]
Остался полностью теоретическим вариантом. Это массив, в котором данные кодируются помехоустойчивым кодом Хэмминга, позволяющим восстанавливать отдельные сбойные фрагменты за счет его избыточности. Кстати различные модификации кода Хэмминга, а также его наследников, используются в процессе считывания данных с магнитных головок жестких дисков и оптических считывателей CD/DVD.
RAID-3 и RAID-4 [ править ]
«Творческое развитие» идеи защиты данных избыточным кодом. Код Хэмминга незаменим в случае «постоянно недостоверного» потока, насыщенного непрерывными слабопредсказуемыми ошибками, такого, например, как зашумленный эфирный канал связи. Однако в случае жестких дисков основная проблема не в ошибках считывания (мы считаем, что данные выдаются жесткими дисками в том виде, в каком мы их записали, если уж он работает), а в выходе из строя целиком диска. Для таких условий можно скомбинировать схему с чередованием (RAID-0) и для защиты от выхода из строя одного из дисков дополнить записываемую информацию избыточностью, которая позволит восстановить данные при потере какой-то ее части, выделив под это дополнительный диск. При потере любого из дисков данных мы можем восстановить хранившиеся на нем данные путем несложных математических операций над данными избыточности, в случае выхода из строя диска с данными избыточности мы все равно имеем данные, считываемые с дискового массива типа RAID-0. Варианты RAID-3 и RAID-4 отличаются тем, что в первом случае чередуются отдельные байты, а во втором — группы байт, «блоки». Основным недостатком этих двух схем является крайне низкая скорость записи на массив, поскольку каждая операция записи вызывает обновление «контрольной суммы», блока избыточности для записанной информации. Очевидно, что, несмотря на структуру с чередованием, производительность массива RAID-3 и RAID-4 ограничена производительностью одного диска, того, на котором лежит «блок избыточности». В «живой природе» в чистом виде почти не встречается. Однако RAID-4 (чередование с четностью с выделенным диском четности) успешно применяется в дисковых системах хранения компании NetApp, где его конструктивные недостатки успешно скомпенсированы особенностями работы файловой системы внутренней OS системы хранения и режимом работы процесса записи данных из кэш-памяти. На сегодняшний день это единственная широко применяемая реализация этого типа.
RAID-5 [ править ]
Попытка обойти это ограничение породила следующий тип RAID, в настоящее время он получил, наряду с RAID-10, наибольшее распространение. Если запись на диск «блока избыточности» ограничивает весь массив, давайте его тоже размажем по дискам массива, сделаем для этой информации невыделенный диск, тем самым операции обновления избыточности окажутся распределенными по всем дискам массива. То есть мы также как и в случае RAID-3(4) берем дисков для хранения N информации в количестве N + 1 диск, но в отличие от Type 3 и 4 этот диск также используется для хранения данных вперемешку с данными избыточности, как и остальные N. Недостатки: Проблема с медленной записью отчасти была решена, но все же не полностью. Запись на массив RAID-5 осуществляется, тем не менее, медленнее, чем на массив RAID-10. Зато RAID-5 более «экономически эффективен». Для RAID-10 мы платим за отказоустойчивость ровно половиной дисков, а в случае RAID-5 это всего один диск.
Тем не менее, поскольку RAID-5 есть наиболее эффективная RAID-структура с точки зрения расхода дисков на «погонный мегабайт» он широко используется там, где снижение скорости записи не является решающим параметром, например для долговременного хранения данных или для данных, преимущественно считываемых. Отдельно следует упомянуть, что расширение дискового массива RAID-5 добавлением дополнительного диска вызывает полное пересчитывание всего RAID, что может занимать часы, а в отдельных случаях и дни, во время которых производительность массива катастрофически падает.
RAID-6 [ править ]
Дальнейшее развитие идеи RAID-5. Если мы рассчитаем дополнительную избыточность по иному нежели применяемому в RAID-5 закону, то мы сможем сохранить доступ к данным при отказе двух дисков массива. Платой за это является дополнительный диск под данные второго «блока избыточности». То есть для хранения данных равных объему N дисков нам нужно будет взять N + 2 диска. Усложняется «математика» вычисления блоков избыточности, что вызывает еще большее снижение скорости записи по сравнению с RAID-5, зато повышается надежность. Причем в ряде случаев она даже превышает уровень надежности RAID-10. Нетрудно увидеть, что RAID-10 тоже выдерживает выход из строя двух дисков в массиве, однако в том случае, если эти диски принадлежат одному «зеркалу» или разным, но при этом не двум зеркальным дискам. А вероятность именно такой ситуации никак нельзя сбрасывать со счета.
комбинированные типы: RAID-10, 50 [ править ]
Дальнейшее увеличение номеров типов RAID происходит за счет «гибридизации», так появляются RAID-0+1 или RAID-10, а также всяческие химерические RAID-51 и так далее. В живой природе к счастью не встречаются, обычно оставаясь «сном разума» (кроме RAID-10).
RAID-10 Попытка объединить достоинства двух типов RAID и лишить их присущих им недостатков. Если взять группу RAID-0 с повышенной производительностью, и придать каждому из них (или массиву целиком) «зеркальные» диски для защиты данных от потери в результате выхода из строя, мы получим отказоустойчивый массив с повышенным, в результате использования чередования, быстродействием. На сегодняшний день «в живой природе» это один из наиболее популярных типов RAID. Минусы — мы платим за все вышеперечисленные достоинства половиной суммарной емкости входящих в массив дисков.
Проприетарные варианты [ править ]
RAID-DP [ править ]
RAID with Diagonal Parity или иногда встречается вариант ‘Double Parity’ — реализованный в 2003 году (впервые появился в версии Data ONTAP 6.5) собственный NetApp-овский аналог RAID-6. Несмотря на то, что RAID-DP в деталях отличается от «канонического» RAID-6, тем не менее в NetApp было принято решение также пользоваться и обозначением RAID-6 для RAID-DP в своей продукции. Это облегчает принципиальное понимание и, кроме прочего, облегчает соответствие систем NetApp тендерным требованиям.
Функционально же, как средство, обеспечивающее защиту данных при выходе из строя двух дисков в RAID-группе, RAID-DP эквивалентен RAID-6. В чем же разница? Практически все вендоры, использующие RAID-6, признают, что использование RAID-6 вместо RAID-5 приводит к падению производительности от 10 до 20 %. Иная ситуация с RAID-DP. Компания NetApp официально подтверждает, что по сравнению с традиционным RAID-4 производительность тома на группе RAID-DP отличается не более чем на единицы процентов.
То есть за повышенную надежность своих данных пользователь системы хранения NetApp не платит производительностью вовсе. Такой результат также является следствием использования все той же тесной интеграции между OS, кэшем, дисками, RAID-структурой и файловой системой. Это позволило Network Appliance рекомендовать использовать RAID-DP как схему по умолчанию для всех своих систем хранения. Однако проприетарность определяет существование этого типа RAID только на системах хранения этого вендора.
RAID-Z [ править ]
Так называемая «программная» реализация RAID осуществляемая на уровне файловой системы ZFS. Выпущена и распространяется под открытой лицензией компанией SUN. Постепенно завоевывает признание. Впервые поддержка появилась в версии ОS SUN Solaris 10, но по причине открытости лицензии и кода может быть перенесена во множество других OS, например, в настоящее время есть реализации во FreeBSD и Mac OS X. По причине конфликта лицензий не поддерживается ядром Linux, но существует реализация в виде user-module под FUSE. «. RAID-Z — реализация RAID-5 без присущих ему недостатков. Основные недостатки RAID-5 — фиксированный размер страйпа и проблема, называемая «write hole». В RAID-5 при модификации неполного страйпа необходимо:
RAID 7.3 [ править ]
Разработан компанией RAIDIX. RAID 7.3 – уровень чередования блоков с тройным распределением чётности, который позволяет восстанавливать данные при отказе до 3-х дисков. В основе RAID 7.3 заложен собственный уникальный алгоритм RAIDIX, позволяющий достигать высоких показателей производительности без дополнительной нагрузки на процессор.
RAID 7.3 является аналогом RAID 6, но имеет более высокую степень надёжности, благодаря расчёту сразу трёх контрольных сумм по разным алгоритмам. Для хранения контрольных сумм отводится ёмкость трёх дисков.
RAID N+M [ править ]
RAID N+M – уровень чередования блоков с M распределением чётности, основанный на проприетарном алгоритме RAIDIX. RAID N+M позволяет пользователю самостоятельно определить количество дисков, выделяемых под хранение контрольных сумм. Уникальная технология RAIDIX позволяет восстановить данные при отказе до 32 дисков (в зависимости от количества дисков, выделяемых под контрольные суммы).
сравнение, преимущества и недостатки [ править ]
Виды систем хранения данных [ править ]
Direct-attached storage (DAS) [ править ]
Под DAS принято понимать непосредственно подключенные к вычислительной системе диски. Обычно как DAS квалифицируются варианты только непосредственного прямого подключения. Так, например, подключение дисков системы хранения данных по каналу FC в режиме «точка-точка» (то есть без «сети хранения», порт системы хранения в порт сервера), несмотря на то, что формально является DAS, тем не менее считается частным, «вырожденным» случаем SAN.
Network-attached storage (NAS) [ править ]
NAS хорошо знаком большинству пользователей, использующих в локальной сети своей организации файловый сервер. Файловый сервер — это NAS. Это устройство, подключенное в локальную сеть и предоставляющее доступ к своим дискам по одному из протоколов «сетевых файловых систем», например CIFS (Common Internet File System) для Windows-систем (раньше называлась SMB — Server Message Blocks) или NFS (Network File System) для UNIX/Linux-систем. Остальные варианты встречаются исчезающе редко.
Storage area network (SAN) [ править ]
SAN-устройство, с точки зрения пользователя, есть просто локальный диск. Обычные варианты протокола доступа к SAN-диску это протокол FibreChannel (FC) и iSCSI (IP-SAN). Для использования SAN в компьютере, который хочет подключиться к SAN, должна быть установлена плата адаптера SAN, которая обычно называется HBA — Host Bus Adapter. Этот адаптер представляет собой с точки зрения компьютера такую своеобразную SCSI-карту и обращается он с ней так же, как с обычной SCSI-картой. Отсылает в нее команды SCSI и получает обратно блоки данных по протоколу SCSI. Наружу же эта карта передает блоки данных и команды SCSI, завернутые в пакеты FC или IP для iSCSI.
Отличия и конвергенция SAN и NAS [ править ]
Каковы же плюсы и минусы обеих этих моделей доступа к данным системы хранения?
Итак, что же общего между этими двумя методами? Оба этих метода используются для «сетевого хранения данных» (networking data storage). Что из них лучше? Единственного ответа не существует. Попытка решить задачи NAS с помощью SAN-системы, как и обратная задача, зачастую есть кратчайший путь потратить большие деньги без видимой выгоды и результата. Каждая из этих «парадигм» имеет свои сильные стороны, каждая имеет оптимальные методы применения.
Content-addressable storage (CAS) [ править ]
CAS так как статья (автор StarMarine) на которую дана ссылка возможно будет удалена, ее содержимое на 03.02.2008 скопировано сюда:
Content-addressable storage (CAS) — архитектура хранения, в которой адресация осуществляется образом хранимых данных. Образ данных хэшируется и хэш используется для его нахождения на устройствах или системах хранения. По сути данные записываются в BLOB-поля специализированной базы данных, а вычисленный хэш используется как индексный ключ базы, по которому осуществляется быстрый поиск содержимого. Построение системы хранения как базы данных позволило применять к процессам доступа и хранения данных методы работы с базами (версионность хранения, дедупликация). Справедливости ради следует также упомянуть, что ранее такие формы организации информации уже применялись на практике, например файловая система OS VMS (применявшаяся на DEC VAX, впоследствии OpenVMS) была организована как своеобразная база данных.
Архитектура обладает большой устойчивостью к дубликатам, а так же может быть выполнена децентрализованно, что дает ей существенную надежность. Однако серьезным недостатком такого способа организации хранения следует назвать невысокое быстродействие, не позволяющее применять CAS в качестве primary storage. В настоящий момент CAS заняли свое место в системах архивного, долговременного и неизменяемого хранения. Наиболее известным производителем CAS-систем на рынке является компания EMC и ее системы серии Centera.
Хороший набор документов: [1]
Эволюция систем хранения данных [ править ]
Технологии, процессы и концепции [ править ]
Резервное копирование (Back-up) [ править ]
стратегии организации резервного копирования [ править ]
полное [ править ]
Полное резервирование обычно затрагивает всю вашу систему и все файлы.
инкрементальное [ править ]
При добавочном («инкрементальном») резервировании происходит копирование только тех файлов, которые были изменены с тех пор, как в последний раз выполнялось полное или добавочное резервное копирование.
дифференциальное [ править ]
При разностном (дифференциальном) резервировании каждый файл, который был изменен с момента последнего полного резервирования, копируется каждый раз заново.
«копирующее» [ править ]
обзор современных решений [ править ]
блочное копирование [ править ]
«непрерывно-инкрементальное» [ править ]
устройства хранения резервных копий [ править ]
ленточные устройства [ править ]
дисковые устройства [ править ]
Репликация [ править ]
синхронная [ править ]
Синхронная репликация — это зеркалирование данных на две системы хранения или два дисковых раздела внутри одной системы. Популярный RAID-1 («зеркало») для дисковых контроллеров есть по сути просто синхронная репликация на два диска, выполняемая контроллером диска. При этом каждый блок данных записывается более или менее одновременно, параллельно, на оба устройства. Аналогичным образом это осуществляется на два «диска» в разных дисковых системах хранения. Это «идеальная репликация», обе копии данных полностью идентичны, потому что пока данные не будут гарантированно записаны на оба устройства, оно не может приступить к записи следующего блока. Однако теоретическая идеальность в реальной жизни оказывается ограничением.
Общая скорость системы ограничена самым узким каналом передачи данных. Если мы соединены с системой хранения FC-каналом в 4GB/s, а система хранения синхронно реплицируется на удаленную систему по каналу в 10MB/s, то скорость обмена по FC-каналу 4GB/s будет только 10MB/s и не больше.
асинхронная [ править ]
Асинхронной называют репликацию, которая осуществляется не в тот же момент, когда осуществляется запись оригинального блока данных, а в «удобное время». Это позволяет преодолеть вышеописанный недостаток синхронной репликации, поскольку процесс записи данных и процесс их переноса на «реплику» разделены и не связаны больше.
При этом сама репликация может быть осуществлена более оптимальным путем, можно провести дополнительную оптимизацию процесса, она может осуществляться по гораздо более дешевым и менее быстродействующим каналам, но копия данных, создаваемая асинхронной репликацией (в отличие от cинхронной), строго говоря, никогда не будет полностью абсолютно идентичной оригиналу, хотя и будет постоянно стремиться к этому соответствию.
«полусинхронная» [ править ]
Вариантом, сочетающим в себе возможности синхронной и асинхронной репликации, является так называемая «semi-synchronous» репликация, или «полусинхронная». В этом случае репликация проводится синхронной до тех пор, пока это позволяет быстродействие системы или канала связи. А затем, вместо замедления и остановки операций записи, временно переключается в асинхронный режим, продолжая обрабатывать поступающие данные без задержек, отправляя данные репликации в асинхронном режиме до тех пор, пока не возникнет возможность восстановить синхронный режим.
плюсы и минусы, критерии выбора [ править ]
Дедупликация [ править ]
теория [ править ]
Дедупликация данных — специализированный метод сжатия массива данных, использующий в качестве алгоритма сжатия исключение дублирующих копий повторяющихся данных. Данный метод обычно используется для оптимизации использования дискового пространства систем хранения данных, однако может применяться и при сетевом обмене данных для сокращения объема передаваемой информации.
В процессе дедупликации во время анализа идентифицируются и запоминаются уникальные элементы информации фиксированного размера (англ. chunks). По мере выполнения анализа сравниваются все новые и новые элементы. При выявлении дублирующегося элемента, он заменяется ссылкой на уникальное вхождение (или на него перенаправляется уже существующая ссылка), а пространство, занимаемое дубликатом, высвобождается. Таких повторяющихся элементов может попадаться очень много, благодаря чему объём, необходимый для сохранения массива данных, может быть сильно сокращён.
Однако дедупликацию не стоит путать с более традиционными алгоритмами сжатия, например LZ77 или LZO. Эти алгоритмы производят поиск в пределах определённого буфера отдельного файла (так называемое «скользящее окно»), тогда как алгоритм дедупликации производит поиск копий по огромному массиву данных.
проблемы и решения [ править ]
Дедупликация способна сократить объём необходимого пространства для определенного набора файлов. Она наиболее эффективна в тех случаях, когда хранимые файлы мало отличимы или имеют много сходных элементов, например в случае резервных копий, где большинство данных остается неизменными с момента прошлой резервной копии. Системы резервирования могут использовать эту особенность, используя жёсткие ссылки на повторяющиеся файлы или копируя только изменённые файлы. Однако эти подходы могут оказаться мало полезными, если у большого блока данных (например, базы данных или архива почтовых сообщений) изменился только небольшой участок данных.
В передаче данных дедупликация может использоваться для сокращения передаваемой информации, что позволяет сэкономить на ширине необходимой пропускной способности канала передачи данных.
Также дедупликация находит широкое применение в системах виртуализации, где дедупликация позволяет условно выделить повторяющиеся элементы данных каждой из виртуальных систем в отдельное пространство.
примеры реализации [ править ]
Иерархическое хранение (HSM) [ править ]
Перемещение (либо автоматическое перемещение в фоновом режиме) пользовательских данных между дисками и/или СХД различных классов стоимости и производительности. Так, например, наиболее востребованные пользовательские данные хранятся на быстрых (Flash, FC) дисках, либо на дисковых массивах Hi-End класса, тогда как данные, к которым давно не было обращения переносятся на более дешевые носители (SAS, SATA), СХД более низкого класса, либо даже на архивные хранилища. Примеры реализации: EMC FAST, Hitachi Tiered Storage Manager (HTSM).
Виртуализация систем хранения [ править ]
Что такое Виртуализация? Для чего она нужна? Пример программно-аппаратного комплекса
Multipathing [ править ]
Доступ к системе хранения данных по двум или более путям. Это позволяет значительно повысить отказоустойчивость и также скорость доступа к СХД. Примеры использования: EMC PowerPath, MPIO, Veritas DMP