Стандартное отклонение
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
Однако, глядя на цифры, можно заметить:
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
5. Поделить на размер выборки (т.е. на n):
6. Найти квадратный корень:
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
Ещё расчёт дисперсии можно сделать по этой формуле:
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
Как найти среднеквадратическое отклонение
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом 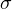 (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее 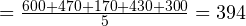 мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
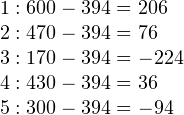
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
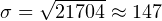 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть 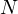 значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
При этом стандартное отклонение по выборке равно 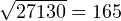 мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
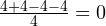 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
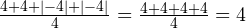 .
.
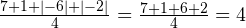 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
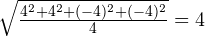 .
.
Для второго примера получится:
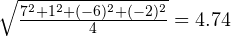 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Среднее квадратическое отклонение




![]()
![]()
Наиболее совершенной характеристикой вариации является среднее квадратическое откложение, которое называют стандартом (или стандартным отклонение). Среднее квадратическое отклонение ( 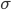 ) равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической:
) равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической:
Среднее квадратическое отклонение простое:
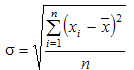
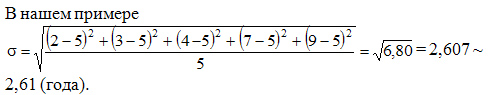
Среднее квадратическое отклонение взвешенное применяется для сгруппированных данных:
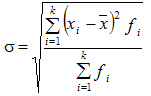
Между средним квадратическим и средним линейным отклонениями в условиях нормального распределения имеет место следующее соотношение:
Среднее квадратическое отклонение, являясь основной абсолютной мерой вариации, используется при определении значений ординат кривой нормального распределения, в расчетах, связанных с организацией выборочного наблюдения и установлением точности выборочных характеристик, а также при оценке границ вариации признака в однородной совокупности.
Дисперсия, ее виды, среднеквадратическое отклонение.
Дисперсия случайной величины — мера разброса данной случайной величины, т. е. её отклонения отматематического ожидания. В статистике часто употребляется обозначение 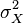 или
или 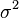 . Квадратный корень из дисперсии
. Квадратный корень из дисперсии 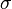 называется среднеквадратичным отклонением, стандартным отклонением или стандартным разбросом.
называется среднеквадратичным отклонением, стандартным отклонением или стандартным разбросом.
Общая дисперсия (σ 2 ) измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. Вместе с тем, благодаря методу группировок можно выделить и измерить вариацию, обусловленную группировочным признаком, и вариацию, возникающую под влиянием неучтенных факторов.
Межгрупповая дисперсия (σ 2 м.гр) характеризует систематическую вариацию, т. е. различия в величине изучаемого признака, возникающие под влиянием признака – фактора, положенного в основание группировки.
Среднеквадратическое отклонение (синонимы: среднее квадратическое отклонение, среднеквадратичное отклонение, квадратичное отклонение; близкие термины: стандартное отклонение, стандартный разброс) — в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величиныотносительно её математического ожидания. При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическоесовокупности выборок.
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами. Определяется какквадратный корень из дисперсии случайной величины.
Среднеквадратическое отклонение:
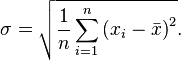
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
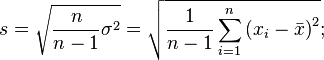
где 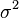 — дисперсия;
— дисперсия; 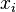 — i-й элемент выборки;
— i-й элемент выборки; 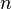 — объём выборки;
— объём выборки; 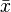 — среднее арифметическое выборки:
— среднее арифметическое выборки:
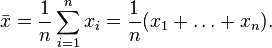
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной.
Сущность, область применения и порядок определения моды и медианы.
Мода — это наиболее часто встречающийся вариант ряда. Мода применяется, например, при определении размера одежды, обуви, пользующейся наибольшим спросом у покупателей. Модой для дискретного ряда является варианта, обладающая наибольшей частотой. При вычислении моды для интервального вариационного ряда необходимо сначала определить модальный интервал (по максимальной частоте), а затем — значение модальной величины признака по формуле:
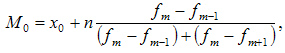
— 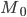 — значение моды
— значение моды
— 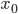 — нижняя граница модального интервала
— нижняя граница модального интервала
— 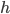 — величина интервала
— величина интервала
— 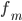 — частота модального интервала
— частота модального интервала

— 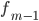 — частота интервала, предшествующего модальному
— частота интервала, предшествующего модальному
— 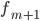 — частота интервала, следующего за модальным
— частота интервала, следующего за модальным
Медиана — это значение признака, которое лежит в основе ранжированного ряда и делит этот ряд на две равные по численности части.
Для определения медианы в дискретном ряду при наличии частот сначала вычисляют полусумму частот 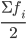 , а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
, а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
Ме = (n(число признаков в совокупности) + 1)/2,
в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
При вычислении медианы для интервального вариационного ряда сначала определяют медианный интервал, в пределах которого находится медиана, а затем — значение медианы по формуле:
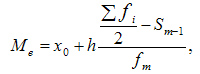
— 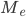 — искомая медиана
— искомая медиана
— — нижняя граница интервала, который содержит медиану
— — величина интервала
—  — сумма частот или число членов ряда
— сумма частот или число членов ряда
— 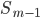 — сумма накопленных частот интервалов, предшествующих медианному
— сумма накопленных частот интервалов, предшествующих медианному
— — частота медианного интервала
Пример. Найти моду и медиану.
| Возрастные группы | Число студентов | Сумма накопленных частот ΣS |
| До 20 лет | ||
| 20 — 25 | ||
| 25 — 30 | ||
| 30 — 35 | ||
| 35 — 40 | ||
| 40 — 45 | ||
| 45 лет и более | ||
| Итого |
Решение:
В данном примере модальный интервал находится в пределах возрастной группы 25-30 лет, так как на этот интервал приходится наибольшая частота (1054).
Рассчитаем величину моды:
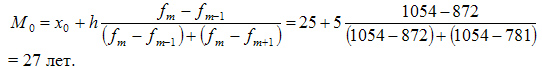
Это значит что модальный возраст студентов равен 27 годам.
Вычислим медиану. Медианный интервал находится в возрастной группе 25-30 лет, так как в пределах этого интервала расположена варианта, которая делит совокупность на две равные части (Σfi/2 = 3462/2 = 1731). Далее подставляем в формулу необходимые числовые данные и получаем значение медианы:
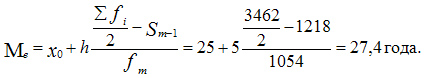
Это значит что одна половина студентов имеет возраст до 27,4 года, а другая свыше 27,4 года.
Кроме моды и медианы могут быть использованы такие показатели, как квартили, делящие ранжированный ряд на 4 равные части, децили — 10 частей и перцентили — на 100 частей.
Понятие выборочного наблюдения и область его применения.
Выборочное наблюдение применяется, когда применение сплошного наблюдения физически невозможно из-за большого массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением, например, дегустация, испытание кирпичей на прочность и т.п.
Качество результатов выборочного наблюдения зависит от репрезентативности выборки, то есть от того, насколько она представительна в ГС. Для обеспечения репрезентативности выборки необходимо соблюдать принцип случайности отбора единиц, который предполагает, что на включение единицы ГС в выборку не может повлиять какой-либо иной фактор кроме случая.
Существует 4 способа случайного отбора в выборку:
Качество выборочных наблюдений зависит и от типа выборки: повторная или бесповторная.
При повторном отборе попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При этом у всех величин генеральной совокупности одинаковая вероятность включения в выборку.
Бесповторный отбор означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку.
Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор.
Предельная ошибка выборки наблюдения, средняя ошибка выборки, порядок их расчета.
Рассмотрим подробно перечисленные выше способы формирования выборочной совокупности и возникающие при этом ошибки репрезентативности.
Собственно-случайная выборка основывается на отборе единиц из генеральной совокупности наугад без каких-либо элементов системности. Технически собственно-случайный отбор проводят методом жеребьевки (например, розыгрыши лотерей) или по таблице случайных чисел.
Собственно-случайный отбор «в чистом виде» в практике выборочного наблюдения применяется редко, но он является исходным среди других видов отбора, в нем реализуются основные принципы выборочного наблюдения. Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Ошибка выборочного наблюдения – это разность между величиной параметра в генеральной совокупности, и его величиной, вычисленной по результатам выборочного наблюдения. Для средней количественного признака ошибка выборки определяется
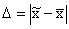
Показатель  называется предельной ошибкой выборки.
называется предельной ошибкой выборки.
Выборочная средняя 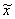 является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки
является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки 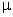 , которая зависит от:
, которая зависит от:
— объема выборки: чем больше численность, тем меньше величина средней ошибки;
— степени изменения изучаемого признака: чем меньше вариация признака, а, следовательно, и дисперсия, тем меньше средняя ошибка выборки.