Spark
Описание термина: Apache Spark или просто Spark — это фреймворк (ПО, объединяющее готовые компоненты большого программного проекта), который используют для параллельной обработки неструктурированных или слабоструктурированных данных.
Например, если нужно обработать данные о годовых продажах одного магазина, то программисту хватит одного компьютера и кода на Python, чтобы произвести расчет. Но если обрабатываются данные от тысяч магазинов из нескольких стран, причем они поступают в реальном времени, содержат пропуски, повторы, ошибки, тогда стоит использовать мощности нескольких компьютеров и Spark. Группа компьютеров, одновременно обрабатывающая данные, называется кластером, поэтому Spark также называют фреймворком для кластерных вычислений.
Зачем нужен Spark
Области использования Spark — это Big Data и технологии машинного обучения, поэтому им пользуются специалисты, работающие с данными, например дата-инженеры, дата-сайентисты и аналитики данных.
Примеры задач, которые можно решить с помощью Spark:
Spark поддерживает языки программирования Scala, Java, Python, R и SQL. Сначала популярными были только первые два, так как на Scala фреймворк был написан, а на Java позже была дописана часть кода. С ростом Python-сообщества этим языком тоже стали пользоваться активнее, правда обновления и новые фичи в первую очередь доступны для Scala-разработчиков. Реже всего для работы со Spark используют язык R.
Data Scientist с нуля
Всего за год вы получите перспективную профессию, пополните портфолио рекомендательной системой и нейросетями, примете участие в соревнованиях на Kaggle и в хакатонах.
В структуру Spark входят ядро для обработки данных и набор расширений:
Как работает Spark
Спарк интегрирован в Hadoop — экосистему инструментов с открытым доступом, в которую входят библиотеки, система управления кластером (Yet Another Resource Negotiator), технология хранения файлов на различных серверах (Hadoop Distributed File System) и система вычислений MapReduce. Классическую модель Hadoop MapReduce и Spark постоянно сравнивают, когда речь заходит об обработке больших данных.
Принципиальные отличия Spark и MapReduce
Пакетная обработка данных
Хранит данные на диске
В 100 раз быстрее, чем MapReduce
Обработка данных в реальном времени
Хранит данные в оперативной памяти
Пакетная обработка в MapReduce проходит на нескольких компьютерах (их также называют узлами) в два этапа: на первом головной узел обрабатывает данные и распределяет их между рабочими узлами, на втором рабочие узлы сворачивают данные и отправляют обратно в головной. Второй шаг пакетной обработки не начнется, пока не завершится первый.
Читайте также: Какой язык учить аналитику данных?
Обработка данных в реальном времени с помощью Spark Streaming — это переход на микропакетный принцип, когда данные постоянно обрабатываются небольшими группами.

Кроме этого, вычисления MapReduce производятся на диске, а Spark производит их в оперативной памяти, и за счет этого его производительность возрастает в 100 раз. Однако специалисты предупреждают, что заявленная «молниеносная скорость работы» Spark не всегда способна решить задачу. Если потребуется обработать больше 10 Тб данных, классический MapReduce доведет вычисление до конца, а вот у Spark может не хватить памяти для такого вычисления.
Но даже сбой в работе кластера не спровоцирует потерю данных. Основу Spark составляют устойчивые распределенные наборы данных (Resilient Distributed Dataset, RDD). Это значит, что каждый датасет хранится на нескольких узлах одновременно и это защищает весь массив.
Освойте самую перспективную профессию 2021 года. После обучения вы будете обладать навыками middle-специалиста и рассчитывать на среднюю зарплату по отрасли.
Разработчики говорят, что до выхода версии Spark 2.0 платформа работала нестабильно, постоянно падала, ей не хватало памяти, и проблемы решались многочисленными обновлениями. Но в 2021 году специалисты уже не сталкиваются с этим, а обновления в основном направлены на расширение функционала и поддержку новых языков.
✅ «Наша компания использует Spark для прогнозирования финансовых рисков»
❌ «Я учусь работать в программе Spark»
Что такое Apache Spark?
Apache Spark — это платформа параллельной обработки с открытым кодом, которая поддерживает обработку в памяти, чтобы повысить производительность приложений, анализирующих большие данные. Решения для работы с большими данными предназначены для обработки данных со слишком большим объемом или сложностью для традиционных баз данных. Spark обрабатывает большие объемы данных в памяти, что намного быстрее, чем альтернативная обработка с использованием диска.
Типичные сценарии обработки больших данных
Следует предусмотреть архитектуру для работы с большими данными, если вам нужно хранить и обрабатывать большие объемы данных, преобразовывать неструктурированные или обрабатывать потоковые данные. Spark предоставляет механизм распределенной обработки широкого назначения, который позволяет реализовать несколько сценариев работы с большими данными.
Извлечение, преобразование и загрузка (ETL)
Процесс извлечения, преобразования и загрузки (ETL) включает сбор данных из одного или нескольких источников, изменение этих данных и их перемещение в новое хранилище. Есть несколько способов преобразовать данные, например:
Обработка потоков данных в реальном времени
Данными потоковой передачи (реального времени) называют данные, которые находятся в движении. К ним относятся, например, данные телеметрии от устройств Интернета вещей, веб-журналы и сведения о посещении ресурсов. Обработка данных реального времени позволяет получить полезные сведения (например, с помощью геопространственного анализа, удаленного мониторинга и обнаружения аномалий). Как и в случае с реляционными данными, перед перемещением потоковых данных в приемник вы можете их фильтровать, объединять и подготавливать. Apache Spark поддерживает обработку потока данных реального времени с помощью потоковой передачи Spark.
Пакетная обработка
Пакетная обработка — это обработка неактивных больших данных. Вы можете фильтровать, объединять и подготавливать очень большие наборы данных с помощью длительно выполняющихся параллельных заданий.
Машинное обучение с использованием MLlib
Машинное обучение позволяет выполнять расширенные аналитические задачи. Ваш компьютер может использовать существующие данные для прогнозирования реакции, результатов и тенденций. Библиотека машинного обучения MLlib из Apache Spark содержит несколько алгоритмов машинного обучения и служебных программ.
Обработка графов с помощью GraphX
Граф — это коллекция узлов, которые соединяются ребрами. Вы можете использовать базу данных графов для иерархических или взаимосвязанных данных. Такие данные можно обрабатывать с помощью API GraphX в Apache Spark.
Обработка SQL и структурированных данных с помощью Spark SQL
Для работы со структурированными (форматированными) данными в приложении Spark можно использовать SQL-запросы с помощью Spark SQL.
Архитектура Apache Spark
Для Apache Spark при использовании архитектуры «основной-рабочий», предусмотрено три основных компонента: драйвер, исполнители и диспетчер кластера.
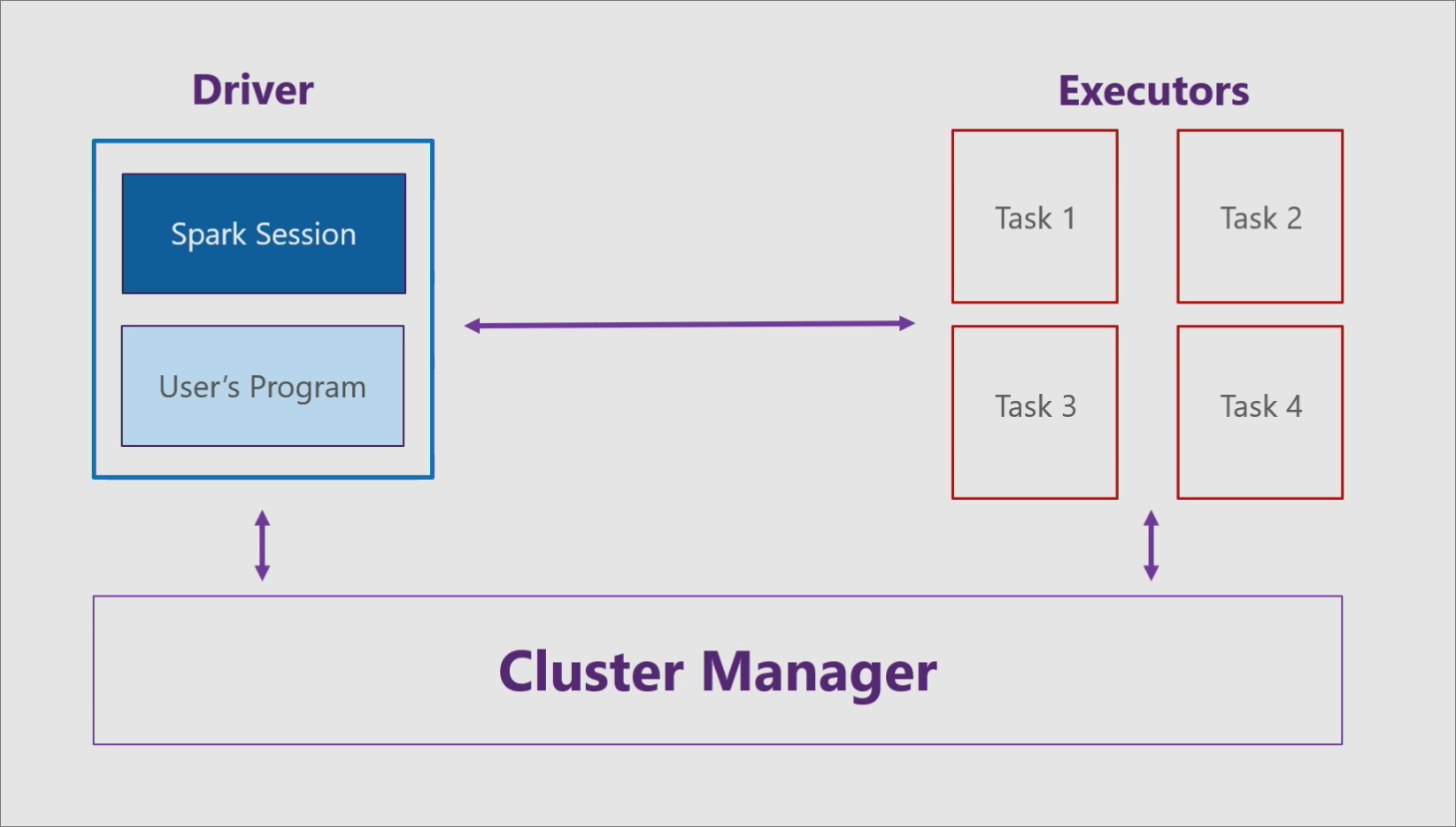
Драйвер
Драйвер состоит из пользовательской программы, например консольного приложения C#, и сеанса Spark. Сеанс Spark принимает программу и делит ее на небольшие задачи, которые обрабатываются исполнителями.
Исполнители
Каждый исполнитель (рабочий узел) получает от драйвера задачу и выполняет ее. Исполнители находятся в сущности, которая называется кластером.
Диспетчер кластера
Диспетчер кластера взаимодействует с драйвером и исполнителями, выполняя следующие задачи:
Поддержка языков
Apache Spark поддерживает следующие языки программирования:
API-интерфейсы Spark
Apache Spark поддерживает следующие API:
Дальнейшие действия
Знакомство с Apache Spark
Здравствуйте, уважаемые читатели!
Мы наконец-то приступаем к переводу серьезной книги о фреймворке Spark:

Сегодня мы предлагаем вашему вниманию перевод обзорной статьи о возможностях Spark, которую, полагаем, можно с полным правом назвать слегка потрясающей.
Я впервые услышал о Spark в конце 2013 года, когда заинтересовался Scala – именно на этом языке написан Spark. Несколько позже я принялся ради интереса разрабатывать проект из области Data Science, посвященный прогнозированию выживаемости пассажиров «Титаника». Оказалось, это отличный способ познакомиться с программированием на Spark и его концепциями. Настоятельно рекомендую познакомиться с ним всем начинающим Spark-разработчикам.
Сегодня Spark применяется во многих крупнейших компаниях, таких, как Amazon, eBay и Yahoo! Многие организации эксплуатируют Spark в кластерах, включающих тысячи узлов. Согласно FAQ по Spark, в крупнейшем из таких кластеров насчитывается более 8000 узлов. Действительно, Spark – такая технология, которую стоит взять на заметку и изучить.

В этой статье предлагается знакомство со Spark, приводятся примеры использования и образцы кода.
Что такое Apache Spark? Введение
Spark – это проект Apache, который позиционируется как инструмент для «молниеносных кластерных вычислений». Проект разрабатывается процветающим свободным сообществом, в настоящий момент является наиболее активным из проектов Apache.
Spark предоставляет быструю и универсальную платформу для обработки данных. По сравнению с Hadoop Spark ускоряет работу программ в памяти более чем в 100 раз, а на диске – более чем в 10 раз.
Кроме того, код на Spark пишется быстрее, поскольку здесь в вашем распоряжении будет более 80 высокоуровневых операторов. Чтобы оценить это, давайте рассмотрим аналог “Hello World!” из мира BigData: пример с подсчетом слов (Word Count). Программа, написанная на Java для MapReduce, содержала бы около 50 строк кода, а на Spark (Scala) нам потребуется всего лишь:
При изучении Apache Spark стоит отметить еще один немаловажный аспект: здесь предоставляется готовая интерактивная оболочка (REPL). При помощи REPL можно протестировать результат выполнения каждой строки кода без необходимости сначала программировать и выполнять все задание целиком. Поэтому написать готовый код удается гораздо быстрее, кроме того, обеспечивается ситуативный анализ данных.
Кроме того, Spark имеет следующие ключевые черты:
Ядро Spark дополняется набором мощных высокоуровневых библиотек, которые бесшовно стыкуются с ним в рамках того же приложения. В настоящее время к таким библиотекам относятся SparkSQL, Spark Streaming, MLlib (для машинного обучения) и GraphX – все они будут подробно рассмотрены в этой статье. Сейчас также разрабатываются другие библиотеки и расширения Spark.
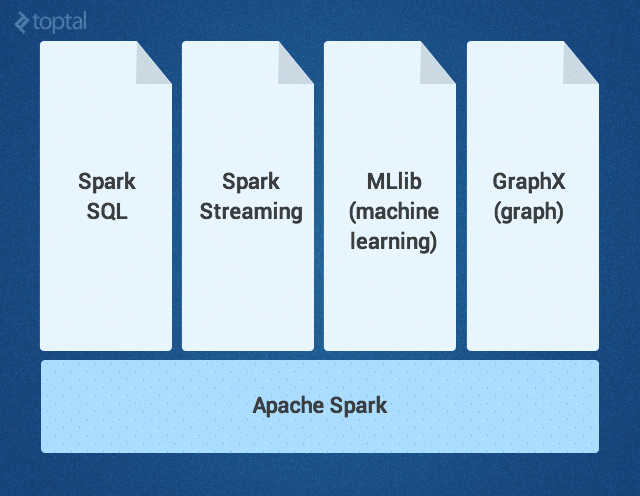
Ядро Spark
Ядро Spark – это базовый движок для крупномасштабной параллельной и распределенной обработки данных. Ядро отвечает за:
Трансформации в Spark осуществляются в «ленивом» режиме — то есть, результат не вычисляется сразу после трансформации. Вместо этого они просто «запоминают» операцию, которую следует произвести, и набор данных (напр., файл), над которым нужно совершить операцию. Вычисление трансформаций происходит только тогда, когда вызывается действие, и его результат возвращается основной программе. Благодаря такому дизайну повышается эффективность Spark. Например, если большой файл был преобразован различными способами и передан первому действию, то Spark обработает и вернет результат лишь для первой строки, а не станет прорабатывать таким образом весь файл.
По умолчанию каждый трансформированный RDD может перевычисляться всякий раз, когда вы выполняете над ним новое действие. Однако RDD также можно долговременно хранить в памяти, используя для этого метод хранения или кэширования; в таком случае Spark будет держать нужные элементы на кластере, и вы сможете запрашивать их гораздо быстрее.
SparkSQL – это компонент Spark, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Библиотека возникла как порт Apache Hive для работы поверх Spark (вместо MapReduce), а сейчас уже интегрирована со стеком Spark. Она не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода; получается очень мощный инструмент. Ниже приведен пример Hive-совместимого запроса:
Spark Streaming поддерживает обработку потоковых данных в реальном времени; такими данными могут быть файлы логов рабочего веб-сервера (напр. Apache Flume и HDFS/S3), информация из соцсетей, например, Twitter, а также различные очереди сообщений вроде Kafka. «Под капотом» Spark Streaming получает входные потоки данных и разбивает данные на пакеты. Далее они обрабатываются движком Spark, после чего генерируется конечный поток данных (также в пакетной форме) как показано ниже.
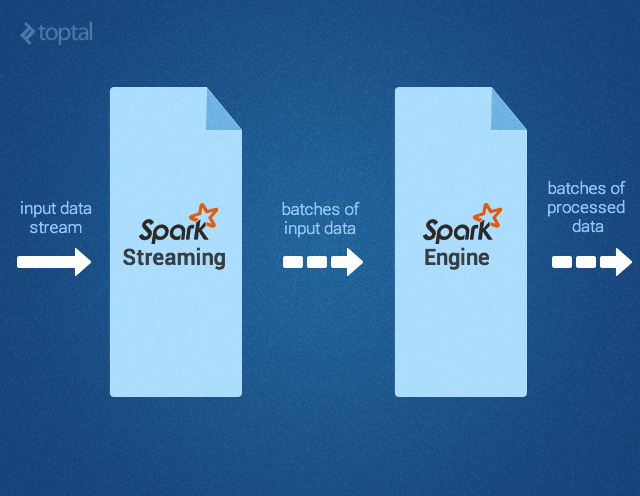
API Spark Streaming точно соответствует API Spark Core, поэтому программисты без труда могут одновременно работать и с пакетными, и с потоковыми данными.
MLlib – это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д. Некоторые из этих алгоритмов работают и с потоковыми данными — например, линейная регрессия с использованием обычного метода наименьших квадратов или кластеризация по методу k-средних (список вскоре расширится). Apache Mahout (библиотека машинного обучения для Hadoop) уже ушла от MapReduce, теперь ее разработка ведется совместно с Spark MLlib.
GraphX – это библиотека для манипуляций над графами и выполнения с ними параллельных операций. Библиотека предоставляет универсальный инструмент для ETL, исследовательского анализа и итерационных вычислений на основе графов. Кроме встроенных операций для манипуляций над графами здесь также предоставляется библиотека обычных алгоритмов для работы с графами, например, PageRank.
Как использовать Apache Spark: пример с обнаружением событий
Теперь, когда мы разобрались, что такое Apache Spark, давайте подумаем, какие задачи и проблемы будут решаться с его помощью наиболее эффективно.
Недавно мне попалась статья об эксперименте по регистрации землетрясений путем анализа потока Twitter. Кстати, в статье было продемонстрировано, что этот метод позволяет узнать о землетрясении более оперативно, чем по сводкам Японского Метеорологического Агентства. Хотя технология, описанная в статье, и не похожа на Spark, этот пример кажется мне интересным именно в контексте Spark: он показывает, как можно работать с упрощенными фрагментами кода и без кода-клея.
Во-первых, потребуется отфильтровать те твиты, которые кажутся нам релевантными – например, с упоминанием «землетрясения» или «толчков». Это можно легко сделать при помощи Spark Streaming, вот так:
Затем нам потребуется произвести определенный семантический анализ твитов, чтобы определить, актуальны ли те толчки, о которых в них говорится. Вероятно, такие твиты, как «Землетрясение!» или «Сейчас трясет» будут считаться положительными результатами, а «Я на сейсмологической конференции» или «Вчера ужасно трясло» — отрицательными. Авторы статьи использовали для этой цели метод опорных векторов (SVM). Мы поступим также, только реализуем еще и потоковую версию. Полученный в результате образец кода из MLlib выглядел бы примерно так:
Если процент верных прогнозов в данной модели нас устраивает, мы можем переходить к следующему этапу: реагировать на обнаруженное землетрясение. Для этого нам потребуется определенное число (плотность) положительных твитов, полученных в определенный промежуток времени (как показано в статье). Обратите внимание: если твиты сопровождаются геолокационной информацией, то мы сможем определить и координаты землетрясения. Вооружившись этими знаниями, мы можем воспользоваться SparkSQL и запросить имеющуюся таблицу Hive (где хранятся данные о пользователях, желающих получать уведомления о землетрясениях), извлечь их электронные адреса и разослать им персонализированные предупреждения, вот так:
Другие варианты использования Apache Spark
Потенциально сфера применения Spark, разумеется, далеко не ограничивается сейсмологией.
Вот ориентировочная (то есть, ни в коем случае не исчерпывающая) подборка других практических ситуаций, где требуется скоростная, разноплановая и объемная обработка больших данных, для которой столь хорошо подходит Spark:
В игровой индустрии: обработка и обнаружение закономерностей, описывающих игровые события, поступающие сплошным потоком в реальном времени; в результате мы можем немедленно на них реагировать и делать на этом хорошие деньги, применяя удержание игроков, целевую рекламу, автокоррекцию уровня сложности и т.д.
В электронной коммерции информация о транзакциях, поступающая в реальном времени, может передаваться в потоковый алгоритм кластеризации, например, по k-средним или подвергаться совместной фильтрации, как в случае ALS. Затем результаты даже можно комбинировать с информацией из других неструктутрированных источников данных — например, с отзывами покупателей или рецензиями. Постепенно эту информацию можно применять для совершенствования рекомендаций с учетом новых тенденций.
В финансовой сфере или при обеспечении безопасности стек Spark может применяться для обнаружения мошенничества или вторжений, либо для аутентификации с учетом анализа рисков. Таким образом можно получать первоклассные результаты, собирая огромные объемы архивированных логов, комбинируя их с внешними источниками данных, например, с информацией об утечках данных или о взломанных аккаунтах (см., например, https://haveibeenpwned.com/), а также использовать информацию о соединениях/запросах, ориентируясь, например, на геолокацию по IP или на данные о времени
Итак, Spark помогает упростить нетривиальные задачи, связанные с большой вычислительной нагрузкой, обработкой больших объемов данных (как в реальном времени, так и архивированных), как структурированных, так и неструктурированных. Spark обеспечивает бесшовную интеграцию сложных возможностей – например, машинного обучения и алгоритмов для работы с графами. Spark несет обработку Big Data в массы. Попробуйте – не пожалеете!
Экспресс-оценка рисков
Пользователям СПАРКа доступны готовые сервисы оценки финансовых рисков, связанных с компанией-контрагентом. Эти сервисы оказывают существенную помощь в экспресс-анализе контрагента и проявлении должной осмотрительности при выборе новых партнеров.
Оценка уровня надежности контрагента в СПАРКе возможна с помощью скоринговых показателей, рассчитывающихся индивидуально для каждой компании на основе имеющихся данных. На карточке компании и ИП отображаются уже готовые индексы, с помощью которых легко выявить потенциальные риски и сократить время на принятие решения:

Сводный индикатор риска
Сводный индикатор риска является совокупной оценкой аналитических показателей, включая Индекс Должной Осмотрительности, Индекс Финансового Риска и Индекс Платежной Дисциплины (см. ниже), а также Статуса компании (состояние ликвидации, банкротства и т.д.).
Представляет собой 3 значения риска: низкий, средний и высокий.
Индекс должной осмотрительности

Индекс Должной Осмотрительности представляет собой значение от 1 до 99, где более высокое значение отражает большую вероятность того, что компания создана не для уставных целей, а в качестве «транзакционной единицы», не имеющей существенных собственных активов и операций, или является «брошенным» активом.
На карточке компании в СПАРКе индикатор отображается в виде светофора: зеленый – низкая опасность, по мере нарастания красного цвета опасность усиливается.
Индекс должной осмотрительности – уникальная скоринговая модель, учитывающая около 20 различных факторов. Индекс рассчитывается практически для всех 3,5 млн действующих в России коммерческих структур.
При разработке модели анализировался международный опыт, детально изучались факторы, свидетельствующие о неблагонадежности компаний, проверялись различные математические методы, на основании которых могут учитываться эти факторы.
Аналитическая модель индекса постоянно дорабатывается, благодаря чему точность оценки, которую он дает, постоянно растет. Это дает возможность повышать уровень прозрачности российского бизнеса, с большей точностью выявлять компании, работа с которыми может оказаться рискованной.
Сегодня около трети доначислений, которые делают налоговые органы, связаны с претензиями, что та или иная компания не проявила должной осмотрительности при выборе контрагента, и он в итоге оказался «однодневкой». Таким образом, «фирмы-однодневки» и транзакционные компании представляют угрозу для законопослушных предпринимателей не только с точки зрения прямой угрозы мошеннических действий, но и с точки зрения налоговых последствий.
Индекс финансового риска

Индекс Финансового Риска представляет собой значение от 1 до 99, где более высокое значение указывает на наличие признаков неудовлетворительного финансового состояния, которые могут привести к тому, что компания утратит платежеспособность.
Для расчета индекса используются комбинированные финансовые коэффициенты компании, такие как коэффициенты ликвидности, достаточности оборотных средств, автономии и другие. Модель построена с использованием нейросетевого моделирования.
Индекс платежной дисциплины

Индекс Платежной Дисциплины (Paydex) представляет собой значение от 0 до 100, где более низкое значение указывает на высокий риск просрочки платежей.
Индекс рассчитывается автоматически на основании данных по платежам компании, полученным от участников программы «Мониторинг платежей».
Зачем нужен индекс:
Источником информации являются данные о своевременности погашения дебиторской задолженности покупателей, полученные от поставщиков товаров/услуг – участников проекта «Мониторинг платежей». Данные передаются ежемесячно, индекс обновляется автоматически по факту загрузки новой информации.
Как формируется индекс:
Факторы риска
При проверке благонадежности контрагента, СПАРК не только дает агрегированную оценку компании в Индексах, но и показывает конкретные факторы риска, на которые необходимо обратить внимание, например:

Всего отслеживается более 40 факторов риска, которые могут свидетельствовать о фактах мошенничества, и на которые стоит обратить внимание при проверке.
Для отдельных факторов используются специальные математические модели с применением временных рядов. Такой подход позволяет выявлять отклонения и всплески показателей, например, это резкий рост исковой нагрузки по отношению к компании со стороны ее контрагентов. Такой фактор сигнализирует о серьезных проблемах у юридического лица и о риске невыполнения обязательств по заключенным договорам и контрактам.
Apache Spark: гайд для новичков

Mar 13, 2020 · 8 min read

Что такое Apache Spark?
Специалисты компании Databricks, основанной создателями Spark, собрали лучшее о функционале Apache Spark в своей книге Gentle Intro to Apache Spark ( очень рекомендую прочитать):
“Apache Spark — это целостная вычислительная система с набором библиотек для п араллельной обработки данных на кластерах компьютеров. На данный момент Spark считается самым активно разрабатываемым средством с открытым кодом для решения подобных задач, что позволяет ему быть полезным инструментом для любого разработчика или исследователя-специалиста, заинтересованного в больших данных. Spark поддерживает множество широко используемых языков программирования (Python, Java, Scala и R), а также библиотеки для различных задач, начиная от SQL и заканчивая стримингом и машинным обучением, а запустить его можно как с ноутбука, так и с кластера, состоящего из тысячи серверов. Благодаря этому Apache Spark и является удобной системой для начала самостоятельной работы, перетекающей в обработку больших данных в невероятно огромных масштабах.”
Что такое большие данные?
Посмотрим-ка на популярное определение больших данных по Гартнеру. Это поможет разобраться в том, как Spark способен решить множество интересных задач, которые связаны с работой с большими данными в реальном времени:
“Большие данные — это информационные активы, которые характеризуются большим объёмом, высокой скоростью и/или многообразием, а также требуют экономически эффективных инновационных форм обработки информации, что приводит к усиленному пониманию, улучшению принятия решений и автоматизации процессов.”

Заметка: Ключевой вывод — слово “большие” в больших данных относится не только к объёму. Вы не просто получаете много данных, они поступают в реальном времени очень быстро и в различных комплексных форматах, а ещё — из большого многообразия источников. Вот откуда появились 3-V больших данных: Volume (Объём), Velocity (Скорость), Variety (Многообразие).
Причины использовать Spark
Основываясь на самостоятельном предварительном исследовании этого вопроса, я пришёл к выводу, что у Apache Spark есть три главных компонента, которые делают его лидером в эффективной работе с большими данными, а это мотивирует многие крупные компании работать с большими наборами неструктурированных данных, чтобы Apache Spark входил в их технологический стек.
Apache Spark или Hadoop MapReduce…Что вам подходит больше?
Если отвечать коротко, то выбор зависит от конкретных потребностей вашего бизнеса, естественно. Подытоживая свои исследования, скажу, что Spark выбирают в 7-ми из 10-ти случаев. Линейная обработка огромных датасетов — преимущество Hadoop MapReduce. Ну а Spark знаменит своей быстрой производительностью, итеративной обработкой, аналитикой в режиме реального времени, обработкой графов, машинным обучением и это ещё не всё.
Хорошие новости в том, что Spark полностью совместим с экосистемой Hadoop и работает замечательно с Hadoop Distributed File System (HDFS — Распределённая файловая система Hadoop), а также с Apache Hive и другими похожими системами. Так что, когда объёмы данных слишком огромные для того, чтобы Spark мог удержать их в памяти, Hadoop может помочь преодолеть это затруднение при помощи возможностей его файловой системы. Привожу ниже пример того, как эти две системы могут работать вместе:

Это изображение наглядно показывает, как Spark использует в работе лучшее от Hadoop: HDFS для чтения и хранения данных, MapReduce — для дополнительной обработки и YARN — для распределения ресурсов.
Дальше я пробую сосредоточиться на множестве преимуществ Spark перед Hadoop MapReduce. Для этого я сделаю краткое поверхностное сравнение.

Скорость
Просто пользоваться
Обработка больших наборов данных
Функциональность
Apache Spark — неизменный победитель в этой категории. Ниже я даю список основных задач по анализу больших данных, в которых Spark опережает Hadoop по производительности:
Машинное обучение. В Spark есть MLlib — встроенная библиотека машинного обучения, а вот Hadoop нужна третья сторона для такого же функционала. MLlib имеет алгоритмы “out-of-the-box” (возможность подключения устройства сразу после того, как его достали из коробки, без необходимости устанавливать дополнительное ПО, драйверы и т.д.), которые также реализуются в памяти.
А вот и визуальный итог множества возможностей Spark и его совместимости с другими инструментами обработки больших данных и языками программирования:

Заключение
Вместе со всем этим массовым распространением больших данных и экспоненциально растущей скоростью вычислительных мощностей инструменты вроде Apache Spark и других программ, анализирующих большие данные, скоро будут незаменимы в работе исследователей данных и быстро станут стандартом в индустрии реализации аналитики больших данных и решении сложных бизнес-задач в реальном времени.
Для тех, кому интересно погрузиться глубоко в технологию, которая стоит за всеми этими внешними функциями, почитайте книгу Databricks — “ A Gentle Intro to Apache Spark” или “ Big Data Analytics on Apache Spark”.