Как важно писать хороший код
Мне приходится очень много читать код. Это и open source, и всяческие фреймворки, и код enterprise приложений. Именно о последних я хотел бы сегодня поговорить.
Большая часть кода enterprise приложений — отстой. Приложения глючат и тормозят, их сложно тестировать, постоянно проблемы с развертыванием и обновлением. Это как бы никого не удивляет.
Но удивляют люди, написавшие отстойный код. Эти люди, с немалым опытом, знают несколько языков, прочитали много книг, знают ООП, SOLID, рефакторинг, паттерны и другие малопонятные слова. То есть примерно такие, как многие из вас, читающих этот пост.
Теория разбитых окон
В 1969 году был проведен эксперимент. В ходе эксперимента две одинаковые машины были оставлены в двух местах – в благополучном университетском городке и неблагополучном районе крупного города. Не удивительно что в неблагополучном месте машина простояла всего пару дней и была выпотрошена, а в благополучном машина простояла нетронутой неделю. Но как только в уцелевшей машине разбили стекло, жители этого самого благополучного городка за несколько часов разобрали её на детали и перевернули вверх дном.
В последствии ученые назвали это явление “Теорией разбитых окон”. Согласно теории, любое проявление беспорядка или нарушение норм провоцирует людей также забыть о правилах. Теория получила несколько экспериментальных подтверждений и её можно считать вполне достоверной.
Есть также и обратный эффект. Поддержание порядка приводит к тому, что окружающие также поддерживают порядок.
Как это влияет на код
В enterprise разработке прессинг сроков и неопределенности требований бывает настолько высок, что кажется сделать “быстро и грязно” – гораздо лучший вариант, чем сделать правильно. Моментально подход “быстро и грязно” начинает распространяться по всему приложению, как путем clipboard inheritance (aka copy-paste), так и за счет эффекта разбитых окон.
Еще один фактор влияющий на качество кода – сложность и несовершенство платформ и фреймворков, используемых в разработке. Из-за этого в коде часто появляются хаки и нелепые workaround-ы. Со временем начинает казаться что эти хаки и есть хороший код. Даже когда проблемы фреймворков исправляют, люди продолжают использовать хаки. Кстати эти хаки со временем могут попадать в интернет через форумы, блоги или pastebin и распространяться далеко за пределы одного приложения.
Вы можете сказать, что качество кода не влияет на качество приложения. Увы, еще как влияет. Программисты допускают ошибки. Чем более плохой код, тем сложнее эти ошибки найти и исправить так, чтобы не создать новых. Прессинг сроков и сложности, скорее всего, не даст написать хороший код и появится еще один хак.
В open source и продуктовой разработке такое встречается реже. Там больше следят за качеством и меньше прессинг сроков.
Код пишется для людей
Часто программисты забывают что код программ пишется в первую очередь для людей. Даже если вы пишите программу в одиночку, то посмотрев на нее через месяц, вы не вспомните почему написали тот или иной кусок кода и за что он отвечает.
Хороший код должен, в первую очередь, очень ясно выражать намерения. К сожалению “быстрые и грязные” способы разработки бьют в первую очередь по понимаемости кода. Улучшение кода осознанно откладывается до лучших времен, когда будет пауза чтобы провести рефакторинг. Те самые лучшие времена никогда не наступают, а код начинают читать и дорабатывать сразу же после попадания в source control.
Даже если вы полностью довольны свои кодом (в большинстве случаев программисты свои кодом довольны), то подумайте о том как будет ваш код читать другой человек (в большинстве случаев программисты недовольны чужим кодом).
Приверженность качеству
Единственный способ добиться высокой продуктивности и эффективности – писать хороший код сразу. Единственный инструмент повышения качества кода – вы сами. Если вы не стремитесь всегда делать хороший код, то вам не помогут ни тесты, ни инструменты статического анализа. Даже ревью других программистов не поможет. Код всегда можно сделать настолько запутанным, что в нем невозможно будет найти ошибку при чтении, при этом сделать вид, что код очень важен и никто не возьмется его переписать.
В первую очередь необходимо думать о структуре и именовании. Код с зашифрованными идентификаторами и малопонятным потоком исполнения скорее всего будет содержать ошибки. Не допускайте такого кода, это гораздо дешевле, чем исправлять ошибки.
Ясно выражайте намерения в своем коде, сводите к минимуму неочевидные неявные аспекты. Не надо стремиться сделать код максимально лаконичным, стремитесь сделать его максимально понятным.
Если вам приходится править код, то не создавайте хаков. Потратьте немного времени, напишите нормально. Сэкономите на поддержке. Если же код совсем плохой, был сделан “быстро и грязно” и оброс хаками, то просто выкиньте его и перепишите. Только не надо пытаться переписать все. Учитывайте продуктивность: программист пишет 40-60 отлаженных строк кода в день в нормальном темпе и 120-200 в ускоренном (высокая концентрация, четкая цель, понятно что делать).
Если вы сами пишете “быстро и грязно”, например прототип для уточнения требований, то выкиньте код и перепишите нормально сразу после того, как ваш код сделает свое дело.
Если вы скопировали часть кода из другого места или, не дай бог, из интернета, то разберитесь как он работает, прежде чем заливать изменения в source control. Вообще не используйте непонятные для вас фрагменты кода.
Всегда поддерживайте чистоту и порядок в вашем коде, пользуйтесь инструментами, которые помогают вам это делать. Не будете этого делать – код очень быстро превратится в помойку. Собирайте статистику по плотности проблем в коде, это поможет вам лучше понять, как писать хороший код.
Перечитывайте свой код. Проводите рефакторинг постоянно в процессе написания. Помните, что рефакторинг “потом” никогда не наступает.
Думайте о том, какой код вы хотите написать, до того как начать его писать. Само написание кода – настолько поглощающий процесс, что думать о качестве некогда. Состояние потока – это состояние свободы самовыражения. Необходимо заранее ограничить самовыражение, чтобы код получился хорошим.
Экономика качества кода
Все знакомы с кривой стоимости ошибки: 
Ошибка найденная и устраненная на этапе кодирования в 10 раз дешевле, чем ошибка найденная при тестировании и в 100 раз дешевле ошибки, найденной в production. В истории есть реальные примеры ошибок, исправление которых обошлось в десятки тысяч долларов.
Поэтому очень важно устранять ошибки на этапе разработки, причем усилиями самих разработчиков.
Что такое хороший код? Считаем звёзды
Никогда такого не было, и вот опять! Опять на прошлой неделе на Хабре появился (и был очень активно комментирован) пост, ныне удалённый, о том, что такое хороший код и чем он отличается от плохого. Яндекс подсказывает, что публикаций о хорошем (вариант: отличном, идеальном, правильном, чистом, грязном, плохом и т.д.) коде здесь уже десятки и сотни, появляются они стабильно на протяжении многих лет, всегда активно обсуждаются, но к единому мнению на этот счёт так и не пришли.
 Этот код тянет как минимум на одну звезду 🙂
Этот код тянет как минимум на одну звезду 🙂
Такой код в настоящее время распространён повсеместно. Причин этому несколько, вот наиболее заметные:
Массовая цифровизация, из-за которой техзадания программистам ставят люди, далёкие от IT (например, руководители заводов) и они в принципе не могут оценить качество кода.
Высокие зарплаты в IT активно привлекают всех-всех-всех, которые трудоустраиваются, пройдя курсы «вайти-вайти за месяц» и имея соответствующие навыки.
Справедливости ради: не всегда это плохо. Если разработка маломасштабная, то её и оптимизировать особо незачем (и так летать будет, ну ведь правда же!). Так или иначе, такой код обычно пишут начинающие программисты и по мере обретения опыта переходят на уровень выше.
Код, который не просто работает, но ещё и работает достаточно быстро. Можно сказать, что этот код оптимизирован по процессорной вычислительной мощности. Одно из формальных определений:
Программа считается эффективной по времени, если время работы программы пропорционально количеству элементов последовательности поступивших данных N, т.е. при увеличении N в k раз время работы программы должно увеличиваться не более чем в k раз.
На практике эффективность по времени иногда определяется не по этому учебно-тренировочному критерию, а по объективным целям и задачам проекта, и может быть задана как относительно («на каждый N не больше k»), так и абсолютно («открывать окно не дольше 0,5 секунды») или даже субъективно («не менее 80% опрошенных согласились, что программа открывается мгновенно»).
Код, который задействует условно небольшое количество памяти при работе. Можно сказать, что он оптимизирован не только по процессорной мощности, но и по оперативной памяти.
Код, который сам имеет минимальный объём. Можно сказать, что он оптимизирован и по процессору, и по оперативке, и по накопителю.
Обычный программист может при желании слегка усечь объём кода: заменив повторяющиеся куски на функции, используя однобуквенные переменные или даже через #define заблаговременно переименовать все команды языка в более краткие, если это оказывается выгодно. Однако всё это, конечно, баловство, которое приносит минимальный результат и в целом скорее вредит. Для того, чтобы принципиально сократить код путём его полной переработки, требуется очень высокая квалификация.
Код, который не только отлично оптимизирован, но и прекрасен: легко читаем, красиво оформлен, в нужных местах прокомментирован, понятен будущим поколениям программистов. Высший пилотаж от мира IT. Дальнейшие комментарии, как говорится, излишни.
Выводы
Понятно, что моя классификация далека от идеала. Например, как классифицировать красиво оформленный, но при этом неоптимизированный код, если оптимизация не очень важна? Поэтому я не претендую на высшую истину в этом вопросе, но надеюсь, что эта заметка поможет приблизиться к таковой, дав пищу для размышлений.
Вероятно, хватит рекомендовать «Чистый код»
Возможно, мы никогда не сможем прийти к эмпирическому определению «хорошего кода» или «чистого кода». Это означает, что мнение одного человека о мнении другого человека о «чистом коде» обязательно очень субъективно. Я не могу рассматривать книгу Роберта Мартина «Чистый код» 2008 года с чужой точки зрения, только со своей.
Тем не менее, для меня главная проблема этой книги заключается в том, что многие примеры кода в ней просто ужасны.
В третьей главе «Функции» Мартин даёт различные советы для написания хороших функций. Вероятно, самый сильный совет в этой главе состоит в том, что функции не должны смешивать уровни абстракции; они не должны выполнять задачи как высокого, так и низкого уровня, потому что это сбивает с толку и запутывает ответственность функции. В этой главе есть и другие важные вещи: Мартин говорит, что имена функций должны быть описательными и последовательными, и должны быть глагольными фразами, и должны быть тщательно выбраны. Он говорит, что функции должны делать только одно, и делать это хорошо. Он говорит, что функции не должны иметь побочных эффектов (и он приводит действительно отличный пример), и что следует избегать выходных аргументов в пользу возвращаемых значений. Он говорит, что функции обычно должны быть либо командами, которые что-то делают, либо запросами, которые на что-то отвечают, но не обоими сразу. Он объясняет DRY. Это всё хорошие советы, хотя немного поверхностные и начального уровня.
Но в этой главе есть и более сомнительные утверждения. Мартин говорит, что аргументы логического флага — плохая практика, с чем я согласен, потому что неприкрашенные true или false в исходном коде непрозрачны и неясны по сравнению с явными IS_SUITE или IS_NOT_SUITE … но рассуждения Мартина скорее сводятся к тому, что логический аргумент означает, что функция делает больше, чем одну вещь, чего она не должна делать.
Мартин говорит, что должно быть возможно читать один исходный файл сверху вниз как повествование, причем уровень абстракции в каждой функции снижается по мере чтения, а каждая функция обращается к другим дальше вниз. Это далеко не универсально. Многие исходные файлы, я бы даже сказал, большинство исходных файлов, нельзя аккуратно иерархизировать таким образом. И даже для тех, которые можно, IDE позволяет нам тривиально прыгать от вызова функции к реализации функции и обратно, точно так же, как мы просматриваем веб-сайты. Кроме того, разве мы по-прежнему читаем код сверху вниз? Ну, может быть, некоторые из нас так и делают.
А потом это становится странным. Мартин говорит, что функции не должны быть достаточно большими, чтобы содержать вложенные структуры (условные обозначения и циклы); они не должны иметь отступов более чем на два уровня. Он говорит, что блоки должны быть длиной в одну строку, состоящие, вероятно, из одного вызова функции. Он говорит, что идеальная функция не имеет аргументов (но всё равно никаких побочных эффектов??), и что функция с тремя аргументами запутанна и трудна для тестирования. Самое странное, что Мартин утверждает, что идеальная функция — это две-четыре строки кода. Этот совет фактически помещен в начале главы. Это первое и самое важное правило:
Первое правило: функции должны быть компактными. Второе правило: функции должны быть ещё компактнее. Я не могу научно обосновать своё утверждение. Не ждите от меня ссылок на исследования, доказывающие, что очень маленькие функции лучше больших. Я могу всего лишь сказать, что я почти четыре десятилетия писал функции всевозможных размеров. Мне доводилось создавать кошмарных монстров в 3000 строк. Я написал бесчисленное множество функций длиной от 100 до 300 строк. И я писал функции от 20 до 30 строк. Мой практический опыт научил меня (ценой многих проб и ошибок), что функции должны быть очень маленькими.
Когда Кент показал мне код, меня поразило, насколько компактными были все функции. Многие из моих функций в программах Swing растягивались по вертикали чуть ли не на километры. Однако каждая функция в программе Кента занимала всего две, три или четыре строки. Все функции были предельно очевидными. Каждая функция излагала свою историю, и каждая история естественным образом подводила вас к началу следующей истории. Вот какими короткими должны быть функции!
Весь этот совет завершается листингом исходного кода в конце главы 3. Этот пример кода является предпочтительным рефакторингом Мартина класса Java, происходящего из опенсорсного инструмента тестирования FitNesse.
Повторю ещё раз: это собственный код Мартина, написанный по его личным стандартам. Это идеал, представленный нам в качестве учебного примера.
На этом этапе я признаюсь, что мои навыки Java устарели и заржавели, почти так же устарели и заржавели, как эта книга, которая вышла в 2008 году. Но ведь даже в 2008 году этот код был неразборчивым мусором?
Давайте проигнорируем import с подстановочными знаками.
Но это неправильное предположение! Вот собственное определение Мартина из более ранней части этой главы:
Побочные эффекты суть ложь. Ваша функция обещает делать что-то одно, но делает что-то другое, скрытое от пользователя. Иногда она вносит неожиданные изменения в переменные своего класса — скажем, присваивает им значения параметров, переданных функции, или глобальных переменных системы. В любом случае такая функция является коварной и вредоносной ложью, которая часто приводит к созданию противоестественных временных привязок и других зависимостей.
Мне нравится это определение! Я согласен с этим определением! Это очень полезное определение! Я согласен, что плохо для функции вносить неожиданные изменения в переменные своего собственного класса.
Так почему же собственный код Мартина, «чистый» код, не делает ничего, кроме этого? Невероятно трудно понять, что делает любой из этих кодов, потому что все эти невероятно крошечные методы почти ничего не делают и работают исключительно через побочные эффекты. Давайте просто рассмотрим один приватный метод.
Мартин утверждает в этой самой главе, что имеет смысл разбить функцию на более мелкие функции, «если вы можете извлечь из неё другую функцию с именем, которое не является просто повторением её реализации». Но потом он даёт нам:
Примечание: некоторые плохие аспекты этого кода не являются виной Мартина. Это рефакторинг уже существующего фрагмента кода, который, по-видимому, изначально не был написан им. Этот код уже имел сомнительный API и сомнительное поведение, оба из которых сохраняются в рефакторинге. Во-первых, имя класса SetupTeardownIncluder ужасно. Это, по крайней мере, именная фраза, как и все имена классов, но это классическая фраза с придушенным глаголом. Это такое имя класса, которое вы неизменно получаете, когда работаете в строго объектно-ориентированном коде, где всё должно быть классом, но иногда вам действительно нужна всего лишь одна простая функция.
*
Неужели вся книга такая?
В основном, да. «Чистый код» смешивает обезоруживающую комбинацию сильных, вечных советов и советов, которые очень сомнительны или устарели. Книга фокусируется почти исключительно на объектно-ориентированном коде и призывает к достоинствам SOLID, исключая другие парадигмы программирования. Он фокусируется на коде Java, исключая другие языки программирования, даже другие объектно-ориентированные языки. Есть глава «Запахи и эвристические правила», которая представляет собой не более чем список довольно разумных признаков, которые следует искать в коде. Но есть несколько в основном пустословных глав, где внимание сосредоточено на трудоёмких отработанных примерах рефакторинга Java-кода. Есть целая глава, изучающая внутренние компоненты JUnit (книга написана в 2008 году, так что вы можете себе представить, насколько это актуально сейчас). Общее использование Java в книге очень устарело. Такого рода вещи неизбежны — книги по программированию традиционно быстро устаревают — но даже для того времени предоставленный код плох.
Там есть глава о модульном тестировании. В этой главе много хорошего — хотя и базового — о том, как модульные тесты должны быть быстрыми, независимыми и воспроизводимыми, о том, как модульные тесты позволяют более уверенно производить рефакторинг исходного кода, о том, что модульные тесты должны быть примерно такими же объёмными, как тестируемый код, но гораздо проще для чтения и понимания. Затем автор показывает модульный тест, где, по его словам, слишком много деталей:
и гордо переделывает его:
Это делается как часть общего урока о ценности изобретения нового языка тестирования для конкретной области для ваших тестов. Я был так сбит с толку этим утверждением. Я бы использовал точно такой же код, чтобы продемонстрировать совершенно противоположный совет! Не делайте этого!
*
Автор представляет три закона TDD:
Первый закон. Не пишите код продукта, пока не напишете отказной модульный тест.
Второй закон. Не пишите модульный тест в объёме большем, чем необходимо для отказа. Невозможность компиляции является отказом.
Третий закон. Не пишите код продукта в объёме большем, чем необходимо для прохождения текущего отказного теста.
Эти три закона устанавливают рамки рабочего цикла, длительность которого составляет, вероятно, около 30 секунд. Тесты и код продукта пишутся вместе, а тесты на несколько секунд опережают код продукта.
… но Мартин не обращает внимания на тот факт, что разбиение задач программирования на крошечные тридцатисекундные кусочки в большинстве случаев безумно трудоёмко, часто очевидно бесполезно, а зачастую невозможно.
*
Есть глава «Объекты и структуры данных», где автор приводит такой пример структуры данных:
и такой пример объекта (ну, интерфейс для одного объекта):
Два предыдущих примера показывают, чем объекты отличаются от структур данных. Объекты скрывают свои данные за абстракциями и предоставляют функции, работающие с этими данными. Структуры данных раскрывают свои данные и не имеют осмысленных функций. А теперь ещё раз перечитайте эти определения. Обратите внимание на то, как они дополняют друг друга, фактически являясь противоположностями. Различия могут показаться тривиальными, но они приводят к далеко идущим последствиям.
Да, вы всё правильно поняли. Определение Мартина «структуры данных» расходится с определением, которое используют все остальные! В книге вообще ничего не говорится о чистом кодировании с использованием того, что большинство из нас считает структурами данных. Эта глава намного короче, чем вы ожидаете, и содержит очень мало полезной информации.
*
Я не собираюсь переписывать все остальные мои заметки. У меня их слишком много, и перечислять всё, что я считаю неправильным в этой книге, заняло бы слишком много времени. Я остановлюсь на ещё одном вопиющем примере кода. Это генератор простых чисел из главы 8:
Если таково качество кода, который создаёт этот программист — на досуге, в идеальных условиях, без давления реальной производственной разработки программного обеспечения — тогда зачем вообще обращать внимание на остальную часть его книги? Или другие его книги?
*
Я написал это эссе, потому что постоянно вижу, как люди рекомендуют «Чистый код». Я почувствовал необходимость предложить антирекомендацию.
Первоначально я читал «Чистый код» в группе на работе. Мы читали по главе в неделю в течение тринадцати недель.
Так вот, вы не хотите, чтобы группа к концу каждого сеанса выражала только единодушное согласие. Вы хотите, чтобы книга вызвала какую-то реакцию у читателей, какие-то дополнительные комментарии. И я предполагаю, что в определённой степени это означает, что книга должна либо сказать что-то, с чем вы не согласны, либо не раскрыть тему полностью, как вы считаете должным. Исходя из этого, «Чистый код» оказался годным. У нас состоялись хорошие дискуссии. Мы смогли использовать отдельные главы в качестве отправной точки для более глубокого обсуждения актуальных современных практик. Мы говорили о многом, что не было описано в книге. Мы во многом расходились во мнениях.
Порекомендовал бы я вам эту книгу? Нет. Даже в качестве текста для начинающих, даже со всеми оговорками выше? Нет. Может быть, в 2008 году я рекомендовал бы вам эту книгу? Могу ли я рекомендовать его сейчас как исторический артефакт, образовательный снимок того, как выглядели лучшие практики программирования в далёком 2008 году? Нет, я бы не стал.
*
Итак, главный вопрос заключается в том, какую книгу(и) я бы рекомендовал вместо этого? Я не знаю. Предлагайте в комментариях, если только я их не закрыл.
Do good code: 8 правил хорошего кода
Практически всем, кто обучался программированию, известна книга Стива Макконнелла «Совершенный код». Она всегда производит впечатление, прежде всего, внушительной толщиной (около 900 страниц). К сожалению, реальность такова, что иногда впечатления этим и ограничиваются. А зря. В дальнейшей профессиональной деятельности программисты сталкиваются практически со всеми ситуациями, описанными в книге, и приходят опытным путём к тем же самым выводам. В то время как более тесное знакомство могло бы сэкономить время и силы. Мы в GeekBrains придерживаемся комплексного подхода в обучении, поэтому провели для слушателей вебинар по правилам создания хорошего кода.

Зачем нужен хороший код, когда всё и так работает?
Несмотря на то, что программа исполняется машиной, программный код пишется людьми и для людей — неслучайно высокоуровневые языки программирования имеют человекопонятные синтаксис и команды. Современные программные проекты разрабатываются группами программистов, порой разделённых не только офисным пространством, но и материками и океанами. Благо, уровень развития технологий позволяет использовать навыки лучших разработчиков, вне зависимости от места нахождения их работодателей. Такой подход к разработке предъявляет серьёзные требования к качеству кода, в частности, к его читабельности и понятности.
Существует множество известных подходов к критериям качества кода, о которых рано или поздно узнаёт практически любой разработчик. Например, есть программисты, которые придерживаются принципа проектирования KISS (Keep It Simple, Stupid! — Делай это проще, тупица!). Этот метод разработки вполне справедлив и заслуживает уважения, к тому же отражает универсальное правило хорошего кода — простоту и ясность. Однако простота должна иметь границы — порядок в программе и читабельность кода не должны быть результатом упрощения. Кроме простоты, существует ещё несколько несложных правил. И они решают ряд задач.
8 правил хорошего кода по версии GeekBrains
Соблюдайте единый Code style. Если программист приходит работать в организацию, особенно крупную, то чаще всего его знакомят с правилами оформления кода в конкретном проекте (соглашение по code style). Это не случайный каприз работодателя, а свидетельство серьёзного подхода.
Вот несколько общих правил, с которыми вы можете столкнуться:
соблюдайте переносы фигурных скобок и отступы — это значительно улучшает восприятие отдельных блоков кода
соблюдайте правило вертикали — части одного запроса или условия должны находиться на одном отступе
соблюдайте разрядку — ставьте пробелы там, где они улучшают читабельность кода; особенно это важно в составных условиях, например, условиях цикла.
В некоторых средах разработки можно изначально задать правила форматирования кода, загрузив настройки отдельным файлом (доступно в Visual Studio). Таким образом, у всех программистов проекта автоматически получается однотипный код, что значительно улучшает восприятие. Известно, что достаточно трудно переучиваться после долгих лет практики и привыкать к новым правилам. Однако в любой компании code style — это закон, которому нужно следовать неукоснительно.
Не используйте «магические числа». Магические числа не случайно относят к анти-паттернам программирования, проще говоря, правилам того, как не надо писать программный код. Чаще всего магическое число как анти-паттерн представляет собой используемую в коде константу, смысл которой неясен без комментария. Такие числа не только усложняют понимание кода и ухудшают его читабельность, но и приносят проблемы во время рефакторинга.
Например, в коде есть строка:
Очевидно, она не вызовет ошибок в работе кода, но и её смысл не всем понятен. Гораздо лучше не полениться и сразу написать таким образом:
Иногда магические числа возникают при использовании общепринятых констант, например, при записи числа π. Допустим, в проекте было внесено:
Что тут плохого? А плохое есть. Например, если в ходе работы понадобится сделать расчёт с высокой точностью, придётся искать все вхождения константы в коде, а это трата трудового ресурса. Поэтому лучше записать так:
Кстати, иногда коллеги-программисты могут не помнить на память значение использованной вами константы — тогда они просто не узнают её в коде. Поэтому лучше избегать написания чисел без объявления в переменных и даже постоянные величины лучше объявлять. Кстати, эти константы практически всегда есть во встроенных библиотеках, поэтому проблема решается сама собой.
Используйте осмысленные имена для переменных, функций, классов. Всем программистам известен термин “обфускация кода” — сознательное запутывание программного года с помощью приложения-обфускатора. Она делается с целью скрыть реализацию и превращает код в невнятный набор символов, переименовывает переменные, меняет имена методов, функций и проч… К сожалению, случается так, что код и без обфускации выглядит запутанно — именно за счёт бессмысленных имён переменных и функций: var_3698, myBestClass, NewMethodFinal и т.д… Это не только мешает разработчикам, которые участвуют в проекте, но и приводит к бесконечному количеству комментариев. Между тем, переименовав функцию, можно избавиться от комментариев — её имя будет само говорить о том, что она делает.
Получится так называемый самодокументируемый код — ситуация, при которой переменные и функции именуются таким образом, что при взгляде на код понятно, как он работает. У идеи самодокументируемого кода есть много сторонников и противников, к аргументам которых стоит прислушаться. Мы рекомендуем в целом соблюдать баланс и разумно использовать и комментарии, и «говорящие» имена переменных, и возможности самодокументируемого кода там, где это оправданно.
Например, возьмём код такого вида:
Из комментария должно быть понятно, что именно делает код. Но совершенно неясно, что обозначают x.a и x.n. Попробуем внести изменения таким образом:
В этом пункте следует отдельно сказать про комментарии, так как слушатели всегда задают очень много вопросов о целесообразности и необходимости их использования. Когда комментариев много, они приводят к низкой читабельности кода. Почти всегда есть возможность внести в код такие изменения, чтобы исчезла потребность в комментарии. В крупных проектах комментарии оправданы в случае использования API, обозначения подключения кода сторонних модулей, обозначения спорных моментов или моментов, требующих дальнейшей переработки.
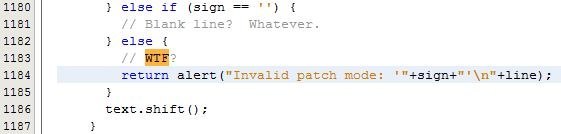
Объединим в одно разъяснение ещё два важных правила. Создавайте методы как новый уровень абстракции с осмысленными именами и делайте методы компактными. Вообще, сегодня модульность кода доступна каждому программисту, а это значит, что нужно стремиться создавать абстракции там, где это возможно. Абстракция — это один из способов сокрытия деталей реализации функциональности. Создавая отдельные небольшие методы, программист получает хороший код, разделённый на блоки, в которых содержится реализация каждой из функций. При таком подходе нередко увеличивается количество строк кода. Есть даже определённые рекомендации, которые указывают длину метода не более 10 строк. Конечно, размер каждого метода остаётся целиком на усмотрении разработчика и зависит от многих факторов. Наш совет: всё просто, делайте метод компактным так, чтобы один метод выполнял одну задачу. Отдельные вынесенные сущности проще улучшить, например, вставить проверку входных данных прямо в начале метода.
Для иллюстрации этих правил возьмём пример из предыдущего пункта и создадим метод, код которого не требует комментариев:
И, наконец, скроем реализацию метода:
В начале методов проверяйте входные данные. На уровне кода нужно обязательно делать проверки входных данных во всех или практически во всех методах. Это связано с пользовательским поведением: будущие пользователи могут вводить любые данные, которые могут вызвать сбои в работе программы. В любом методе, даже в том, который использовался всего один раз, обязательно нужно организовывать проверку данных и создавать обработку ошибок. Это стоит сделать, поскольку метод не только выступает как уровень абстракции, но и необходим для переиспользования. В принципе, возможно разделить методы на те, в которых нужно делать проверку, и те, в которых её делать необязательно, но для полной уверенности и защиты от «хитрого пользователя» лучше проверять все входные данные.
В примере ниже вставляем проверку на то, чтобы на входе не получить null.
Реализуйте при помощи наследования только отношение «является». В остальных случаях – композиция. Композиция является одним из ключевых паттернов, нацеленных на облегчение восприятия кода и, в отличие от наследования, не нарушает принцип инкапсуляции. Допустим, у вас есть класс Руль и класс Колесо. Класс Автомобиль можно реализовать как наследник класса-предка Руль, но ведь Автомобилю нужны и свойства класса Колесо.
Соответственно, программист начинает плодить наследование. А ведь даже с точки зрения обывательской логики класс Автомобиль — это композиция элементов. Допустим, есть такой код, когда новый класс создаётся с использованием наследования (класс ScreenElement наследует поля и методы класса Coordinate и расширяет этот класс):
Композиция — неплохая замена наследованию, этот паттерн более простой для дальнейшего понимания написанного кода. Можно придерживаться такого правила: выбирать наследование, только если нужный класс схож с классом-предком и не будет использовать методы других классов. К тому же, композиция избавляет программиста ещё от одной проблемы — исключает конфликт имён, который случается при наследовании. Есть у композиции и недостаток: размножение количества объектов может оказывать влияние на производительность. Но опять же, это зависит от масштаба проекта и должно оцениваться разработчиком в каждом случае отдельно.
Отделяйте интерфейс от реализации. Любой используемый в программе класс состоит из интерфейса (того, что доступно при использовании класса извне) и реализации (методы). В коде интерфейс должен быть отделён от реализации как для соблюдения одного из принципов ООП, инкапсуляции, так и для улучшения читабельности кода.
Второй случай предпочтительнее, так как он скрывает реализацию с помощью модификатора доступа private. Кроме улучшения читабельности кода, отделение интерфейса от реализации в сочетании с соблюдением правила создания небольшого интерфейса даёт ещё одно важное преимущество: в случае нарушений в работе программы для поиска причины сбоя потребуется проверить лишь несколько функций. Чем больше открытых функций и данных — тем сложнее отследить источник ошибки. Однако интерфейс должен быть полным и должен позволять делать всё, что необходимо, иначе он бесполезен.
В ходе вебинара был задан вопрос: «А можно писать сразу хорошо и не рефакторить?» Вероятно, через несколько лет или даже десятков лет программирования это будет возможно, особенно если есть изначальное видение архитектуры программы. Но никогда нельзя предвидеть конечное состояние проекта через несколько релизов и итераций доработки. Именно поэтому важно всегда помнить о перечисленных правилах, которые гарантируют устойчивость и способность вашей программы к развитию.
Для тех, кто воспринимает информацию через видео и хочет услышать детали вебинара — видеоверсия:
Другие наши вебинары можно посмотреть здесь.